Jeff Atwood, perhaps the most widely read programming blogger, has a post that makes a case against using ECC memory. My read is that his major points are:
- Google didn't use ECC when they built their servers in 1999
- Most RAM errors are hard errors and not soft errors
- RAM errors are rare because hardware has improved
- If ECC were actually important, it would be used everywhere and not just servers. Paying for optional stuff like this is "awfully enterprisey"
Let's take a look at these arguments one by one:
1. Google didn't use ECC in 1999
Not too long after Google put these non-ECC machines into production, they realized this was a serious error and not worth the cost savings. If you think cargo culting what Google does is a good idea because it's Google, here are some things you might do:
A. Put your servers into shipping containers.
Articles are still written today about what a great idea this is, even though this was an experiment at Google that was deemed unsuccessful. Turns out, even Google's experiments don't always succeed. In fact, their propensity for “moonshots” in the early days meannt that they had more failed experiments that most companies. Copying their failed experiments isn't a particularly good strategy.
B. Cause fires in your own datacenters
Part of the post talks about how awesome these servers are:
Some people might look at these early Google servers and see an amateurish fire hazard. Not me. I see a prescient understanding of how inexpensive commodity hardware would shape today's internet. I felt right at home when I saw this server; it's exactly what I would have done in the same circumstances
The last part of that is true. But the first part has a grain of truth, too. When Google started designing their own boards, one generation had a regrowth issue that caused a non-zero number of fires.
BTW, if you click through to Jeff's post and look at the photo that the quote refers to, you'll see that the boards have a lot of flex in them. That caused problems and was fixed in the next generation. You can also observe that the cabling is quite messy, which also caused problems, and was also fixed in the next generation. There were other problems as well. Jeff's argument here appears to be that, if he were there at the time, he would've seen the exact same opportunities that early Google enigneers did, and since Google did this, it must've been the right thing even if it doesn't look like it. But, a number of things that make it look like not the right thing actually made it not the right thing.
C. Make servers that injure your employees
One generation of Google servers had infamously sharp edges, giving them the reputation of being made of “razor blades and hate”.
D. Create weather in your datacenters
From talking to folks at a lot of large tech companies, it seems that most of them have had a climate control issue resulting in clouds or fog in their datacenters. You might call this a clever plan by Google to reproduce Seattle weather so they can poach MS employees. Alternately, it might be a plan to create literal cloud computing. Or maybe not.
Note that these are all things Google tried and then changed. Making mistakes and then fixing them is common in every successful engineering organization. If you're going to cargo cult an engineering practice, you should at least cargo cult current engineering practices, not something that was done in 1999.
When Google used servers without ECC back in 1999, they found a number of symptoms that were ultimately due to memory corruption, including a search index that returned effectively random results to queries. The actual failure mode here is instructive. I often hear that it's ok to ignore ECC on these machines because it's ok to have errors in individual results. But even when you can tolerate occasional errors, ignoring errors means that you're exposing yourself to total corruption, unless you've done a very careful analysis to make sure that a single error can only contaminate a single result. In research that's been done on filesystems, it's been repeatedly shown that despite making valiant attempts at creating systems that are robust against a single error, it's extremely hard to do so and basically every heavily tested filesystem can have a massive failure from a single error (see the output of Andrea and Remzi's research group at Wisconsin if you're curious about this). I'm not knocking filesystem developers here. They're better at that kind of analysis than 99.9% of programmers. It's just that this problem has been repeatedly shown to be hard enough that humans cannot effectively reason about it, and automated tooling for this kind of analysis is still far from a push-button process. In their book on warehouse scale computing, Google discusses error correction and detection and ECC is cited as their slam dunk case for when it's obvious that you should use hardware error correction.
Google has great infrastructure. From what I've heard of the infra at other large tech companies, Google's sounds like the best in the world. But that doesn't mean that you should copy everything they do. Even if you look at their good ideas, it doesn't make sense for most companies to copy them. They created a replacement for Linux's work stealing scheduler that uses both hardware run-time information and static traces to allow them to take advantage of new hardware in Intel's server processors that lets you dynamically partition caches between cores. If used across their entire fleet, that could easily save Google more money in a week than stackexchange has spent on machines in their entire history. Does that mean you should copy Google? No, not unless you've already captured all the lower hanging fruit, which includes things like making sure that your core infrastructure is written in highly optimized C++, not Java or (god forbid) Ruby. And the thing is, for the vast majority of companies, writing in a language that imposes a 20x performance penalty is a totally reasonable decision.
2. Most RAM errors are hard errors
The case against ECC quotes this section of a study on DRAM errors (the bolding is Jeff's):
Our study has several main findings. First, we find that approximately 70% of DRAM faults are recurring (e.g., permanent) faults, while only 30% are transient faults. Second, we find that large multi-bit faults, such as faults that affects an entire row, column, or bank, constitute over 40% of all DRAM faults. Third, we find that almost 5% of DRAM failures affect board-level circuitry such as data (DQ) or strobe (DQS) wires. Finally, we find that chipkill functionality reduced the system failure rate from DRAM faults by 36x.
This seems to betray a lack of understanding of the implications of this study, as this quote doesn't sound like an argument against ECC; it sounds like an argument for "chipkill", a particular class of ECC. Putting that aside, Jeff's post points out that hard errors are twice as common as soft errors, and then mentions that they run memtest on their machines when they get them. First, a 2:1 ratio isn't so large that you can just ignore soft errors. Second the post implies that Jeff believes that hard errors are basically immutable and can't surface after some time, which is incorrect. You can think of electronics as wearing out just the same way mechanical devices wear out. The mechanisms are different, but the effects are similar. In fact, if you compare reliability analysis of chips vs. other kinds of reliability analysis, you'll find they often use the same families of distributions to model failures. And, if hard errors were immutable, they would generally get caught in testing by the manufacturer, who can catch errors much more easily than consumers can because they have hooks into circuits that let them test memory much more efficiently than you can do in your server or home computer. Third, Jeff's line of reasoning implies that ECC can't help with detection or correction of hard errors, which is not only incorrect but directly contradicted by the quote.
So, how often are you going to run memtest on your machines to try to catch these hard errors, and how much data corruption are you willing to live with? One of the key uses of ECC is not to correct errors, but to signal errors so that hardware can be replaced before silent corruption occurs. No one's going to consent to shutting down everything on a machine every day to run memtest (that would be more expensive than just buying ECC memory), and even if you could convince people to do that, it won't catch as many errors as ECC will.
When I worked at a company that owned about 1000 machines, we noticed that we were getting strange consistency check failures, and after maybe half a year we realized that the failures were more likely to happen on some machines than others. The failures were quite rare, maybe a couple times a week on average, so it took a substantial amount of time to accumulate the data, and more time for someone to realize what was going on. Without knowing the cause, analyzing the logs to figure out that the errors were caused by single bit flips (with high probability) was also non-trivial. We were lucky that, as a side effect of the process we used, the checksums were calculated in a separate process, on a different machine, at a different time, so that an error couldn't corrupt the result and propagate that corruption into the checksum. If you merely try to protect yourself with in-memory checksums, there's a good chance you'll perform a checksum operation on the already corrupted data and compute a valid checksum of bad data unless you're doing some really fancy stuff with calculations that carry their own checksums (and if you're that serious about error correction, you're probably using ECC regardless). Anyway, after completing the analysis, we found that memtest couldn't detect any problems, but that replacing the RAM on the bad machines caused a one to two order of magnitude reduction in error rate. Most services don't have this kind of checksumming we had; those services will simply silently write corrupt data to persistent storage and never notice problems until a customer complains.
3. Due to advances in hardware manufacturing, errors are very rare
Jeff says
I do seriously question whether ECC is as operationally critical as we have been led to believe [for servers], and I think the data shows modern, non-ECC RAM is already extremely reliable ... Modern commodity computer parts from reputable vendors are amazingly reliable. And their trends show from 2012 onward essential PC parts have gotten more reliable, not less. (I can also vouch for the improvement in SSD reliability as we have had zero server SSD failures in 3 years across our 12 servers with 24+ drives ...
and quotes a study.
The data in the post isn't sufficient to support this assertion. Note that since RAM usage has been increasing and continues to increase at a fast exponential rate, RAM failures would have to decrease at a greater exponential rate to actually reduce the incidence of data corruption. Furthermore, as chips continue shrink, features get smaller, making the kind of wearout issues discussed in “2” more common. For example, at 20nm, a DRAM capacitor might hold something like 50 electrons, and that number will get smaller for next generation DRAM and things continue to shrink.
The 2012 study that Atwood quoted has this graph on corrected errors (a subset of all errors) on ten randomly selected failing nodes (6% of nodes had at least one failure):
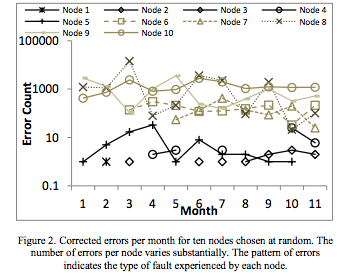
We're talking between 10 and 10k errors for a typical node that has a failure, and that's a cherry-picked study from a post that's arguing that you don't need ECC. Note that the nodes here only have 16GB of RAM, which is an order of magnitude less than modern servers often have, and that this was on an older process node that was less vulnerable to noise than we are now. For anyone who's used to dealing with reliability issues and just wants to know the FIT rate, the study finds a FIT rate of between 0.057 and 0.071 faults per Mbit (which, contra Atwood's assertion, is not a shockingly low number). If you take the most optimistic FIT rate, .057, and do the calculation for a server without much RAM (here, I'm using 128GB, since the servers I see nowadays typically have between 128GB and 1.5TB of RAM)., you get an expected value of .057 * 1000 * 1000 * 8760 / 1000000000 = .5 faults per year per server. Note that this is for faults, not errors. From the graph above, we can see that a fault can easily cause hundreds or thousands of errors per month. Another thing to note is that there are multiple nodes that don't have errors at the start of the study but develop errors later on. So, in fact, the cherry-picked study that Jeff links contradicts Jeff's claim about reliability.
Sun/Oracle famously ran into this a number of decades ago. Transistors and DRAM capacitors were getting smaller, much as they are now, and memory usage and caches were growing, much as they are now. Between having smaller transistors that were less resilient to transient upset as well as more difficult to manufacture, and having more on-chip cache, the vast majority of server vendors decided to add ECC to their caches. Sun decided to save a few dollars and skip the ECC. The direct result was that a number of Sun customers reported sporadic data corruption. It took Sun multiple years to spin a new architecture with ECC cache, and Sun made customers sign an NDA to get replacement chips. Of course there's no way to cover up this sort of thing forever, and when it came up, Sun's reputation for producing reliable servers took a permanent hit, much like the time they tried to cover up poor performance results by introducing a clause into their terms of services disallowing benchmarking.
Another thing to note here is that when you're paying for ECC, you're not just paying for ECC, you're paying for parts (CPUs, boards) that have been qual'd more thoroughly. You can easily see this with disk failure rates, and I've seen many people observe this in their own private datasets. In terms of public data, I believe Andrea and Remzi's group had a SIGMETRICS paper a few years back that showed that SATA drives were 4x more likely than SCSI drives to have disk read failures, and 10x more likely to have silent data corruption. This relationship held true even with drives from the same manufacturer. There's no particular reason to think that the SCSI interface should be more reliable than the SATA interface, but it's not about the interface. It's about buying a high-reliability server part vs. a consumer part. Maybe you don't care about disk reliability in particular because you checksum everything and can easily detect disk corruption, but there are some kinds of corruption that are harder to detect.
[2024 update, almost a decade later]: looking at this retrospectively, we can see that Jeff's assertion that commodity parts are reliable, "modern commodity computer parts from reputable vendors are amazingly reliable" is still not true. Looking at real-world user data from Firefox, Gabriele Svelto estimated that approximately 10% to 20% of all Firefox crashes were due to memory corruption. Various game companies that track this kind of thing also report a significant fraction of user crashes appear to be due to data corruption, although I don't have an estimate from any of those companies handy. A more direct argument is that if you talk to folks at big companies that run a lot of ECC memory and look at the rate of ECC errors, there are quite a few errors detected by ECC memory despite ECC memory typically having a lower error rate than random non-ECC memory. This kind of argument is frequently made (here, it was detailed above a decade ago, and when I looked at this when I worked at Twitter fairly recently and there has not been a revolution in memory technology that has reduced the need for ECC over the rates discussed in papers a decade ago), but it often doesn't resontate with folks who say things like "well, those bits probably didn't matter anyway", "most memory ends up not getting read", etc. Looking at real-world crashes and noting that the amount of silent data corruption should be expected to be much higher than the rate of crashes seems to resonate with people who aren't excited by looking at raw FIT rates in datacenters.
4. If ECC were actually important, it would be used everywhere and not just servers.
One way to rephrase this is as a kind of cocktail party efficient markets hypothesis. This can't be important, because if it was, we would have it. Of course this is incorrect and there are many things that would be beneficial to consumers that we don't have, such as cars that are designed to safe instead of just getting the maximum score in crash tests. Looking at this with respect to the server and consumer markets, this argument can be rephrased as “If this feature were actually important for servers, it would be used in non-servers”, which is incorrect. A primary driver of what's available in servers vs. non-servers is what can be added that buyers of servers will pay a lot for, to allow for price discrimination between server and non-server parts. This is actually one of the more obnoxious problems facing large cloud vendors — hardware vendors are able to jack up the price on parts that have server features because the features are much more valuable in server applications than in desktop applications. Most home users don't mind, giving hardware vendors a mechanism to extract more money out of people who buy servers while still providing cheap parts for consumers.
Cloud vendors often have enough negotiating leverage to get parts at cost, but that only works where there's more than one viable vendor. Some of the few areas where there aren't any viable competitors include CPUs and GPUs. There have been a number of attempts by CPU vendors to get into the server market, but each attempt so far has been fatally flawed in a way that made it obvious from an early stage that the attempt was doomed (and these are often 5 year projects, so that's a lot of time to spend on a doomed project). The Qualcomm effort has been getting a lot of hype, but when I talk to folks I know at Qualcomm they all tell me that the current chip is basically for practice, since Qualcomm needed to learn how to build a server chip from all the folks they poached from IBM, and that the next chip is the first chip that has any hope of being competitive. I have high hopes for Qualcomm as well an ARM effort to build good server parts, but those efforts are still a ways away from bearing fruit.
The near total unsuitability of current ARM (and POWER) options (not including hypothetical variants of Apple's impressive ARM chip) for most server workloads in terms of performance per TCO dollar is a bit of a tangent, so I'll leave that for another post, but the point is that Intel has the market power to make people pay extra for server features, and they do so. Additionally, some features are genuinely more important for servers than for mobile devices with a few GB of RAM and a power budget of a few watts that are expected to randomly crash and reboot periodically anyway.
Conclusion
Should you buy ECC RAM? That depends. For servers, it's probably a good bet considering the cost, although it's hard to really do a cost/benefit analysis because it's really hard to figure out the cost of silent data corruption, or the cost of having some risk of burning half a year of developer time tracking down intermittent failures only to find that the were caused by using non-ECC memory.
For normal desktop use, I'm pro-ECC, but if you don't have regular backups set up, doing backups probably has a better ROI than ECC. But once you have the absolute basics set up, there's a fairly strong case for ECC for consumer machines. For example, if you have backups without ECC, you can easily write corrupt data into your primary store and replicate that corrupt data into backup. But speaking more generally, big companies running datacenters are probably better set up to detect data corruption and more likely to have error correction at higher levels that allow them to recover from data corruption than consumers, so the case for consumers is arguably stronger than it is for servers, where the case is strong enough that's generally considered a no brainer. A major reason consumers don't generally use ECC isn't that it isn't worth it for them, it's that they just have no idea how to attribute crashes and data corruption when they happen. Once you start doing this, as Google and other large companies do, it's immediately obvious that ECC is worth the cost even when you have multiple levels of error correction operating at higher levels. This is analogous to what we see with files, where big tech companies write software for their datacenters that's much better at dealing with data corruption than big tech companies that write consumer software (and this is often true within the same company). To the user, the cost of having their web app corrupt their data isn't all that different from when their desktop app corrupts their data, the difference is that when their web app corrupts data, it's clearer that it's the company's fault, which changes the incentives for companies.
Appendix: security
If you allow any sort of code execution, even sandboxed execution, there are attacks like rowhammer which can allow users to cause data corruption and there have been instances where this has allowed for privilege escalation. ECC doesn't completely mitigate the attack, but it makes it much harder.
Thanks to Prabhakar Ragde, Tom Murphy, Jay Weisskopf, Leah Hanson, Joe Wilder, and Ralph Corderoy for discussion/comments/corrections. Also, thanks (or maybe anti-thanks) to Leah for convincing me that I should write up this off the cuff verbal comment as a blog post. Apologies for any errors, the lack of references, and the stilted prose; this is basically a transcription of half of a conversation and I haven't explained terms, provided references, or checked facts in the level of detail that I normally do.