This is a response to the following question from David Albert:
My mental model of CPUs is stuck in the 1980s: basically boxes that do arithmetic, logic, bit twiddling and shifting, and loading and storing things in memory. I'm vaguely aware of various newer developments like vector instructions (SIMD) and the idea that newer CPUs have support for virtualization (though I have no idea what that means in practice).
What cool developments have I been missing? What can today's CPU do that last year's CPU couldn't? How about a CPU from two years ago, five years ago, or ten years ago? The things I'm most interested in are things that programmers have to manually take advantage of (or programming environments have to be redesigned to take advantage of) in order to use and as a result might not be using yet. I think this excludes things like Hyper-threading/SMT, but I'm not honestly sure. I'm also interested in things that CPUs can't do yet but will be able to do in the near future.
Everything below refers to x86 and linux, unless otherwise indicated. History has a tendency to repeat itself, and a lot of things that were new to x86 were old hat to supercomputing, mainframe, and workstation folks.
The Present
Miscellania
For one thing, chips have wider registers and can address more memory. In the 80s, you might have used an 8-bit CPU, but now you almost certainly have a 64-bit CPU in your machine. I'm not going to talk about this too much, since I assume you're familiar with programming a 64-bit machine. In addition to providing more address space, 64-bit mode provides more registers and more consistent floating point results (via the avoidance of pseudo-randomly getting 80-bit precision for 32 and 64 bit operations via x87 floating point). Other things that you're very likely to be using that were introduced to x86 since the early 80s include paging / virtual memory, pipelining, and floating point.
Esoterica
I'm also going to avoid discussing things that are now irrelevant (like A20M) and things that will only affect your life if you're writing drivers, BIOS code, doing security audits, or other unusually low-level stuff (like APIC/x2APIC, SMM, NX, or SGX).
Memory / Caches
Of the remaining topics, the one that's most likely to have a real effect on day-to-day programming is how memory works. My first computer was a 286. On that machine, a memory access might take a few cycles. A few years back, I used a Pentium 4 system where a memory access took more than 400 cycles. Processors have sped up a lot more than memory. The solution to the problem of having relatively slow memory has been to add caching, which provides fast access to frequently used data, and prefetching, which preloads data into caches if the access pattern is predictable.
A few cycles vs. 400+ cycles sounds really bad; that's well over 100x slower. But if I write a dumb loop that reads and operates on a large block of 64-bit (8-byte) values, the CPU is smart enough to prefetch the correct data before I need it, which lets me process at about 22 GB/s on my 3GHz processor. A calculation that can consume 8 bytes every cycle at 3GHz only works out to 24GB/s, so getting 22GB/s isn't so bad. We're losing something like 8% performance by having to go to main memory, not 100x.
As a first-order approximation, using predictable memory access patterns and operating on chunks of data that are smaller than your CPU cache will get you most of the benefit of modern caches. If you want to squeeze out as much performance as possible, this document is a good starting point. After digesting that 100 page PDF, you'll want to familiarize yourself with the microarchitecture and memory subsystem of the system you're optimizing for, and learn how to profile the performance of your application with something like likwid.
TLBs
There are lots of little caches on the chip for all sorts of things, not just main memory. You don't need to know about the decoded instruction cache and other funny little caches unless you're really going all out on micro-optimizations. The big exception is the TLBs, which are caches for virtual memory lookups (done via a 4-level page table structure on x86). Even if the page tables were in the l1-data cache, that would be 4 cycles per lookup, or 16 cycles to do an entire virtual address lookup each time around. That's totally unacceptable for something that's required for all user-mode memory accesses, so there are small, fast, caches for virtual address lookups.
Because the first level TLB cache has to be fast, it's severely limited in size (perhaps 64 entries on a modern chip). If you use 4k pages, that limits the amount of memory you can address without incurring a TLB miss. x86 also supports 2MB and 1GB pages; some applications will benefit a lot from using larger page sizes. It's something worth looking into if you've got a long-running application that uses a lot of memory.
Also, first-level caches are usually limited by the page size times the associativity of the cache. If the cache is smaller than that, the bits used to index into the cache are the same regardless if whether you're looking at the virtual address or the physical address, so you don't have to do a virtual to physical translation before indexing into the cache. If the cache is larger than that, you have to first do a TLB lookup to index into the cache (which will cost at least one extra cycle), or build a virtually indexed cache (which is possible, but adds complexity and coupling to software). You can see this limit in modern chips. Haswell has an 8-way associative cache and 4kB pages. Its l1 data cache is 8 * 4kB = 32kB.
Out of Order Execution / Serialization
For a couple decades now, x86 chips have been able to speculatively execute and re-order execution (to avoid blocking on a single stalled resource). This sometimes results in odd performance hiccups. But x86 is pretty strict in requiring that, for a single CPU, externally visible state, like registers and memory, must be updated as if everything were executed in order. The implementation of this involves making sure that, for any pair of instructions with a dependency, those instructions execute in the correct order with respect to each other.
That restriction that things look like they executed in order means that, for the most part, you can ignore the existence of OoO execution unless you're trying to eke out the best possible performance. The major exceptions are when you need to make sure something not only looks like it executed in order externally, but actually executed in order internally.
An example of when you might care would be if you're trying to measure the execution time of a sequence of instructions using rdtsc. rdtsc reads a hidden internal counter and puts the result into edx and eax, externally visible registers.
Say we do something like
foo
rdtsc
bar
mov %eax, [%ebx]
baz
where foo, bar, and baz don't touch eax, edx, or [%ebx]. The mov that follows the rdtsc will write the value of eax to some location in memory, and because eax is an externally visible register, the CPU will guarantee that the mov doesn't execute until after rdtsc has executed, so that everything looks like it happened in order.
However, since there isn't an explicit dependency between the rdtsc and either foo or bar, the rdtsc could execute before foo, between foo and bar, or after bar. It could even be the case that baz executes before the rdtsc, as long as baz doesn't affect the move instruction in any way. There are some circumstances where that would be fine, but it's not fine if the rdtsc is there to measure the execution time of foo.
To precisely order the rdtsc with respect to other instructions, we need to an instruction that serializes execution. Precise details on how exactly to do that are provided in this document by Intel.
Memory / Concurrency
In addition to the ordering restrictions above, which imply that loads and stores to the same location can't be reordered with respect to each other, x86 loads and stores have some other restrictions. In particular, for a single CPU, stores are never reordered with other stores, and stores are never reordered with earlier loads, regardless of whether or not they're to the same location.
However, loads can be reordered with earlier stores. For example, if you write
mov 1, [%esp]
mov [%ebx], %eax
it can be executed as if you wrote
mov [%ebx], %eax
mov 1, [%esp]
But the converse isn't true — if you write the latter, it can never be executed as if you wrote the former.
You could force the first example to execute as written by inserting a serializing instruction. But that requires the CPU to serialize all instructions. But that's slow, since it effectively forces the CPU to wait until all instructions before the serializing instruction are done before executing anything after the serializing instruction. There's also an mfence instruction that only serializes loads and stores, if you only care about load/store ordering.
I'm not going to discuss the other memory fences, lfence and sfence, but you can read more about them here.
We've looked at single core ordering, where loads and stores are mostly ordered, but there's also multi-core ordering. The above restrictions all apply; if core0 is observing core1, it will see that all of the single core rules apply to core1's loads and stores. However, if core0 and core1 interact, there's no guarantee that their interaction is ordered.
For example, say that core0 and core 1 start with eax and edx set to 0, and core 0 executes
mov 1, [_foo]
mov [_foo], %eax
mov [_bar], %edx
while core1 executes
mov 1, [_bar]
mov [_bar], %eax
mov [_foo], %edx
For both cores, eax has to be 1 because of the within-core dependency between the first instruction and the second instruction. However, it's possible for edx to be 0 in both cores because line 3 of core0 can execute before core0 sees anything from core1, and visa versa.
That covers memory barriers, which serialize memory accesses within a core. Since stores are required to be seen in a consistent order across cores, they can, they also have an effect on cross-core concurrency, but it's pretty difficult to reason about that kind of thing correctly. Linus has this to say on using memory barriers instead of locking:
The real cost of not locking also often ends up being the inevitable bugs. Doing clever things with memory barriers is almost always a bug waiting to happen. It's just really hard to wrap your head around all the things that can happen on ten different architectures with different memory ordering, and a single missing barrier. … The fact is, any time anybody makes up a new locking mechanism, THEY ALWAYS GET IT WRONG. Don't do it.
And it turns out that on modern x86 CPUs, using locking to implement concurrency primitives is often cheaper than using memory barriers, so let's look at locks.
If we set _foo to 0 and have two threads that both execute incl (_foo) 10000 times each, incrementing the same location with a single instruction 20000 times, is guaranteed not to exceed 20000, but it could (theoretically) be as low as 2. If it's not obvious why the theoretical minimum is 2 and not 10000, figuring that out is a good exercise. If it is obvious, my bonus exercise for you is, can any reasonable CPU implementation get that result, or is that some silly thing the spec allows that will never happen? There isn't enough information in this post to answer the bonus question, but I believe I've linked to enough information.
We can try this with a simple code snippet
#include <stdlib.h>
#include <thread>
#define NUM_ITERS 10000
#define NUM_THREADS 2
int counter = 0;
int *p_counter = &counter;
void asm_inc() {
int *p_counter = &counter;
for (int i = 0; i < NUM_ITERS; ++i) {
__asm__("incl (%0) \n\t" : : "r" (p_counter));
}
}
int main () {
std::thread t[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; ++i) {
t[i] = std::thread(asm_inc);
}
for (int i = 0; i < NUM_THREADS; ++i) {
t[i].join();
}
printf("Counter value: %i\n", counter);
return 0;
}
Compiling the above with clang++ -std=c++11 -pthread, I get the following distribution of results on two of my machines:
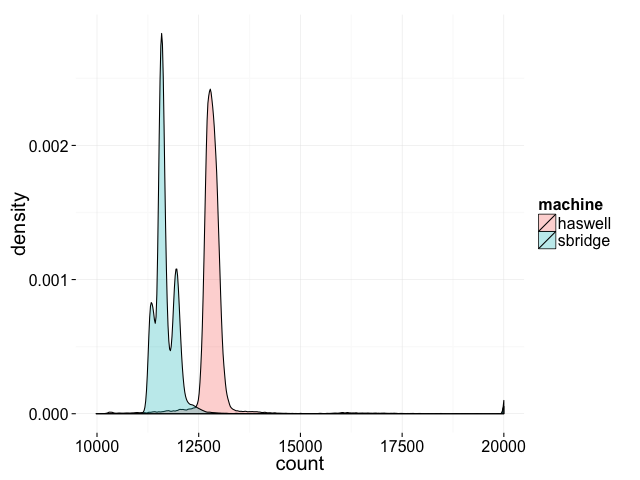
Not only do the results vary between runs, the distribution of results is different on different machines. We never hit the theoretical minimum of 2, or for that matter, anything below 10000, but there's some chance of getting a final result anywhere between 10000 and 20000.
Even though incl is a single instruction, it's not guaranteed to be atomic. Internally, incl is implemented as a load followed by an add followed by an store. It's possible for an increment on cpu0 to sneak in and execute between the load and the store on cpu1 and visa versa.
The solution Intel has for this is the lock prefix, which can be added to a handful of instructions to make them atomic. If we take the above code and turn incl into lock incl, the resulting output is always 20000.
So, that's how we make a single instruction atomic. To make a sequence atomic, we can use xchg or cmpxchg, which are always locked as compare-and-swap primitives. I won't go into detail about how that works, but see this article by David Dalrymple if you're curious..
In addition to making a memory transaction atomic, locks are globally ordered with respect to each other, and loads and stores aren't re-ordered with respect to locks.
For a rigorous model of memory ordering, see the x86 TSO doc.
All of this discussion has been how about how concurrency works in hardware. Although there are limitations on what x86 will re-order, compilers don't necessarily have those same limitations. In C or C++, you'll need to insert the appropriate primitives to make sure the compiler doesn't re-order anything. As Linus points out here, if you have code like
local_cpu_lock = 1;
// .. do something critical ..
local_cpu_lock = 0;
the compiler has no idea that local_cpu_lock = 0 can't be pushed into the middle of the critical section. Compiler barriers are distinct from CPU memory barriers. Since the x86 memory model is relatively strict, some compiler barriers are no-ops at the hardware level that tell the compiler not to re-order things. If you're using a language that's higher level than microcode, assembly, C, or C++, your compiler probably handles this for you without any kind of annotation.
Memory / Porting
If you're porting code to other architectures, it's important to note that x86 has one of the strongest memory models of any architecture you're likely to encounter nowadays. If you write code that just works without thinking it through and port it to architectures that have weaker guarantees (PPC, ARM, or Alpha), you'll almost certainly have bugs.
Consider this example:
Initial
-----
x = 1;
y = 0;
p = &x;
CPU1 CPU2
---- ----
i = *p; y = 1;
MB;
p = &y;
MB is a memory barrier. On an Alpha 21264 system, this can result in i = 0.
Kourosh Gharachorloo explains how:
CPU2 does y=1 which causes an "invalidate y" to be sent to CPU1. This invalidate goes into the incoming "probe queue" of CPU1; as you will see, the problem arises because this invalidate could theoretically sit in the probe queue without doing an MB on CPU1. The invalidate is acknowledged right away at this point (i.e., you don't wait for it to actually invalidate the copy in CPU1's cache before sending the acknowledgment). Therefore, CPU2 can go through its MB. And it proceeds to do the write to p. Now CPU1 proceeds to read p. The reply for read p is allowed to bypass the probe queue on CPU1 on its incoming path (this allows replies/data to get back to the 21264 quickly without needing to wait for previous incoming probes to be serviced). Now, CPU1 can derefence p to read the old value of y that is sitting in its cache (the invalidate y in CPU1's probe queue is still sitting there).
How does an MB on CPU1 fix this? The 21264 flushes its incoming probe queue (i.e., services any pending messages in there) at every MB. Hence, after the read of p, you do an MB which pulls in the invalidate to y for sure. And you can no longer see the old cached value for y.
Even though the above scenario is theoretically possible, the chances of observing a problem due to it are extremely minute. The reason is that even if you setup the caching properly, CPU1 will likely have ample opportunity to service the messages (i.e., invalidate) in its probe queue before it receives the data reply for "read p". Nonetheless, if you get into a situation where you have placed many things in CPU1's probe queue ahead of the invalidate to y, then it is possible that the reply to p comes back and bypasses this invalidate. It would be difficult for you to set up the scenario though and actually observe the anomaly.
This is long enough without my talking about other architectures so I won't go into detail, but if you're wondering why anyone would create a spec that allows this kind of optimization, consider that before rising fab costs crushed DEC, their chips were so fast that they could run industry standard x86 benchmarks of real workloads in emulation faster than x86 chips could run the same benchmarks natively. For more explanation of why the most RISC-y architecture of the time made the decisions it did, see this paper on the motivations behind the Alpha architecture.
BTW, this is a major reason I'm skeptical of the Mill architecture. Putting aside arguments about whether or not they'll live up to their performance claims, being technically excellent isn't, in and of itself, a business model.
Memory / Non-Temporal Stores / Write-Combine Memory
The set of restrictions outlined in the previous section apply to cacheable (i.e., “write-back” or WB) memory. That, itself, was new at one time. Before that, there was only uncacheable (UC) memory.
One of the interesting things about UC memory is that all loads and stores are expected to go out to the bus. That's perfectly reasonable in a processor with no cache and little to no on-board buffering. A result of that is that devices that have access to memory can rely on all accesses to UC memory regions creating separate bus transactions, in order (because some devices will use a memory read or write as as trigger to do something). That worked great in 1982, but it's not so great if you have a video card that just wants to snarf down whatever the latest update is. If multiple writes happen to the same UC location (or different bytes of the same word), the CPU is required to issue a separate bus transaction for each write, even though a video card doesn't really care about seeing each intervening result.
The solution to that was to create a memory type called write combine (WC). WC is a kind of eventually consistent UC. Writes have to eventually make it to memory, but they can be buffered internally. WC memory also has weaker ordering guarantees than UC.
For the most part, you don't have to deal with this unless you're talking directly with devices. The one exception are “non-temporal” load and store operations. These make particular loads and stores act like they're to WC memory, even if the address is in a memory region that's marked WB.
This is useful if you don't want to pollute your caches with something. This is often useful if you're doing some kind of streaming calculation where you know you're not going to use a particular piece of data more than once.
Memory / NUMA
Non-uniform memory access, where memory latencies and bandwidth are different for different processors, is so common that we mostly don't talk about NUMA or ccNUMA anymore because they're so common that it's assumed to be the default.
The takeaway here is that threads that share memory should be on the same socket, and a memory-mapped I/O heavy thread should make sure it's on the socket that's closest to the I/O device it's talking to.
I've mostly avoided explaining the why behind things because that would make this post at least an order of magnitude longer than it's going to be. But I'll give a vastly oversimplified explanation of why we have NUMA systems, partially because it's a self-contained thing that's relatively easy to explain and partially to demonstrate how long the why is compared to the what.
Once upon a time, there was just memory. Then CPUs got fast enough relative to memory that people wanted to add a cache. It's bad news if the cache is inconsistent with the backing store (memory), so the cache has to keep some information about what it's holding on to so it knows if/when it needs to write things to the backing store.
That's not too bad, but once you get 2 cores with their own caches, it gets a little more complicated. To maintain the same programming model as the no-cache case, the caches have to be consistent with each other and with the backing store. Because existing load/store instructions have nothing in their API that allows them to say sorry! this load failed because some other CPU is holding onto the address you want, the simplest thing was to have every CPU send a message out onto the bus every time it wanted to load or store something. We've already got this memory bus that both CPUs are connected to, so we just require that other CPUs respond with the data (and invalidate the appropriate cache line) if they have a modified version of the data in their cache.
That works ok. Most of the time, each CPU only touches data the other CPU doesn't care about, so there's some wasted bus traffic. But it's not too bad because once a CPU puts out a message saying Hi! I'm going to take this address and modify the data, it can assume it completely owns that address until some other CPU asks for it, which will probably won't happen. And instead of doing things on a single memory address, we can operate on cache lines that have, say, 64 bytes. So, the overall overhead is pretty low.
It still works ok for 4 CPUs, although the overhead is a bit worse. But this thing where each CPU has to respond to every other CPU's fails to scale much beyond 4 CPUs, both because the bus gets saturated and because the caches will get saturated (the physical size/cost of a cache is O(n^2) in the number of simultaneous reads and write supported, and the speed is inversely correlated to the size).
A “simple” solution to this problem is to have a single centralized directory that keeps track of all the information, instead of doing N-way peer-to-peer broadcast. Since we're packing 2-16 cores on a chip now anyway, it's pretty natural to have a single directory per chip (socket) that tracks the state of the caches for every core on a chip.
This only solves the problem for each chip, and we need some way for the chips to talk to each other. Unfortunately, while we were scaling these systems up the bus speeds got fast enough that it's really difficult to drive a signal far enough to connect up a bunch of chips and memory all on one bus, even for small systems. The simplest solution to that is to have each socket own a region of memory, so every socket doesn't need to be connected to every part of memory. This also avoids the complexity of needed a higher level directory of directories, since it's clear which directory owns any particular piece of memory.
The disadvantage of this is that if you're sitting in one socket and want some memory owned by another socket, you have a significant performance penalty. For simplicity, most “small” (< 128 core) systems use ring-like busses, so the performance penalty isn't just the direct latency/bandwidth penalty you pay for walking through a bunch of extra hops to get to memory, it also uses up a finite resource (the ring-like bus) and slows down other cross-socket accesses.
In theory, the OS handles this transparently, but it's often inefficient.
Context Switches / Syscalls
Here, syscall refers to a linux system call, not the SYSCALL or SYSENTER x86 instructions.
A side effect of all the caching that modern cores have is that context switches are expensive, which causes syscalls to be expensive. Livio Soares and Michael Stumm discuss the cost in great detail in their paper. I'm going to use a few of their figures, below. Here's a graph of how many instructions per clock (IPC) a Core i7 achieves on Xalan, a sub-benchmark from SPEC CPU.
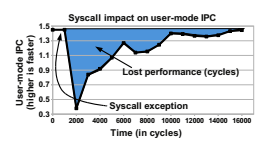
14,000 cycles after a syscall, code is still not quite running at full speed.
Here's a table of the footprint of a few different syscalls, both the direct cost (in instructions and cycles), and the indirect cost (from the number of cache and TLB evictions).
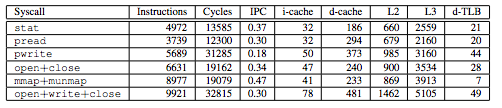
Some of these syscalls cause 40+ TLB evictions! For a chip with a 64-entry d-TLB, that nearly wipes out the TLB. The cache evictions aren't free, either.
The high cost of syscalls is the reason people have switched to using batched versions of syscalls for high-performance code (e.g., epoll, or recvmmsg) and the reason that people who need very high performance I/O often use user space I/O stacks. More generally, the cost of context switches is why high-performance code is often thread-per-core (or even single threaded on a pinned thread) and not thread-per-logical-task.
This high cost was also the driver behind vDSO, which turns some simple syscalls that don't require any kind of privilege escalation into simple user space library calls.
SIMD
Basically all modern x86 CPUs support SSE, 128-bit wide vector registers and instructions. Since it's common to want to do the same operation multiple times, Intel added instructions that will let you operate on a 128-bit chunk of data as 2 64-bit chunks, 4 32-bit chunks, 8 16-bit chunks, etc. ARM supports the same thing with a different name (NEON), and the instructions supported are pretty similar.
It's pretty common to get a 2x-4x speedup from using SIMD instructions; it's definitely worth looking into if you've got a computationally heavy workload.
Compilers are good enough at recognizing common patterns that can be vectorized that simple code, like the following, will automatically use vector instructions with modern compilers
for (int i = 0; i < n; ++i) {
sum += a[i];
}
But compilers will often produce non-optimal code if you don't write the assembly by hand, especially for SIMD code, so you'll want to look at the disassembly and check for compiler optimization bugs if you really care about getting the best possible performance.
Power Management
There are a lot of fancy power management feature on modern CPUs that optimize power usage in different scenarios. The result of these is that “race to idle”, completing work as fast as possible and then letting the CPU go back to sleep is the most power efficient way to work.
There's been a lot of work that's shown that specific microoptmizations can benefit power consumption, but applying those microoptimizations on real workloads often results in smaller than expected benefits.
GPU / GPGPU
I'm even less qualified to talk about this than I am about the rest of this stuff. Luckily, Cliff Burdick volunteered to write a section on GPUs, so here it is.
Prior to the mid-2000's, Graphical Processing Units (GPUs) were restricted to an API that allowed only a very limited amount of control of the hardware. As the libraries became more flexible, programmers began using the processors for more general-purpose tasks, such as linear algebra routines. The parallel architecture of the GPU could work on large chunks of a matrix by launching hundreds of simultaneous threads. However, the code had to use traditional graphics APIs and was still limited in how much of the hardware it could control. Nvidia and ATI took notice and released frameworks that allowed the user to access more of the hardware with an API familiar with people outside of the graphics industry. The libraries gained popularity, and today GPUs are widely used for high-performance computing (HPC) alongside CPUs.
Compared to CPUs, the hardware on GPUs have a few major differences, outlined below:
Processors
At the top level, a GPU processor contains one or many streaming multiprocessors (SMs). Each streaming multiprocessor on a modern GPU typically contains over 100 floating point units, or what are typically referred to as cores in the GPU world. Each core is typically clocked around 800MHz, although, like CPUs, processors with higher clock rates but fewer cores are also available. GPU processors lack many features of their CPU counterparts, including large caches and branch prediction. Between the layers of cores, SMs, and the overall processor, communicating becomes increasingly slower. For this reason, problems that perform well on GPUs are typically highly-parallel, but have some amount of data that can be shared between a small number of threads. We'll get into why this is in the memory section below.
Memory
Memory on modern GPU is broken up into 3 main categories: global memory, shared memory, and registers. Global memory is the GDDR memory that's advertised on the box of the GPU and is typically around 2-12GB in size, and has a throughput of 300-400GB/s. Global memory can be accessed by all threads across all SMs on the processor, and is also the slowest type of memory on the card. Shared memory is, as the name says, memory that's shared between all threads within the same SM. It is usually at least twice as fast as global memory, but is not accessible between threads on different SMs. Registers are much like registers on a CPU in that they are the fastest way to access data on a GPU, but they are local per thread and the data is not visible to any other running thread. Both shared memory and global memory have very strict rules on how they can be accessed, with severe performance penalties for not following them. To reach the throughputs mentioned above, memory accesses must be completely coalesced between threads within the same thread group. Similar to a CPU reading into a single cache line, GPUs have cache lines sized so that a single access can serve all threads in a group if aligned properly. However, in the worst case where all threads in a group access memory in a different cache line, a separate memory read will be required for each thread. This usually means that most of the data in the cache line is not used by the thread, and the usable throughput of the memory goes down. A similar rule applies to shared memory as well, with a couple exceptions that we won't cover here.
Threading Model
GPU threads run in a SIMT (Single Instruction Multiple Thread) fashion, and each thread runs in a group with a pre-defined size in the hardware (typically 32). That last part has many implications; every thread in that group must be working on the same instruction at the same time. If any of the threads in a group need to take a divergent path (an if statement, for example) of code from the others, all threads not part of the branch suspend execution until the branch is complete. As a trivial example:
if (threadId < 5) {
// Do something
}
// Do More
In the code above, this branch would cause 27 of our 32 threads in the group to suspend execution until the branch is complete. You can imagine if many groups of threads all run this code, the overall performance will take a large hit while most of the cores sit idle. Only when an entire group of threads is stalled is the hardware allowed to swap in another group to run on those cores.
Interfaces
Modern GPUs must have a CPU to copy data to and from CPU and GPU memory, and to launch and code on the GPU. At the highest throughput, a PCIe 3.0 bus with 16 lanes can achieves rates of about 13-14GB/s. This may sound high, but when compared to the memory speeds residing on the GPU itself, they're over an order of magnitude slower. In fact, as GPUs get more powerful, the PCIe bus is increasingly becoming a bottleneck. To see any of the performance benefits the GPU has over a CPU, the GPU must be loaded with a large amount of work so that the time the GPU takes to run the job is significantly higher than the time it takes to copy the data to and from.
Newer GPUs have features to launch work dynamically in GPU code without returning to the CPU, but it's fairly limited in its use at this point.
GPU Conclusion
Because of the major architectural differences between CPUs and GPUs, it's hard to imagine either one replacing the other completely. In fact, a GPU complements a CPU well for parallel work and allows the CPU to work independently on other tasks as the GPU is running. AMD is attempting to merge the two technologies with their "Heterogeneous System Architecture" (HSA), but taking existing CPU code and determining how to split it between the CPU and GPU portion of the processor will be a big challenge not only for the processor, but for compilers as well.
Virtualization
Since you mentioned virtualization, I'll talk about it a bit, but Intel's implementation of virtualization instructions generally isn't something you need to think about unless you're writing very low-level code that directly deals with virtualization.
Dealing with that stuff is pretty messy, as you can see from this code. Setting stuff up to use Intel's VT instructions to launch a VM guest is about 1000 lines of low-level code, even for the very simple case shown there.
Virtual Memory
If you look at Vish's VT code, you'll notice that there's a decent chunk of code dedicated to page tables / virtual memory. That's another “new” feature that you don't have to worry about unless you're writing an OS or other low-level systems code. Using virtual memory is much simpler than using segmented memory, but that's not relevant nowadays so I'll just leave it at that.
SMT / Hyper-threading
Since you brought it up, I'll also mention SMT. As you said, this is mostly transparent for programmers. A typical speedup for enabling SMT on a single core is around 25%. That's good for overall throughput, but it means that each thread might only get 60% of its original performance. For applications where you care a lot about single-threaded performance, you might be better off disabling SMT. It depends a lot on the workload, though, and as with any other changes, you should run some benchmarks on your exact workload to see what works best.
One side effect of all this complexity that's been added to chips (and software) is that performance is a lot less predictable than it used to be; the relative importance of benchmarking your exact workload on the specific hardware it's going to run on has gone up.
Just for example, people often point to benchmarks from the Computer Languages Benchmarks Game as evidence that one language is faster than another. I've tried reproducing the results myself, and on my mobile Haswell (as opposed to the server Kentsfield that's used in the results), I get results that are different by as much as 2x (in relative speed). Running the same benchmark on the same machine, Nathan Kurz recently pointed me to an example where gcc -O3 is 25% slower than gcc -O2. Changing the linking order on C++ programs can cause a 15% performance change. Benchmarking is a hard problem.
Branches
Old school conventional wisdom is that branches are expensive, and should be avoided at all (or most) costs. On a Haswell, the branch misprediction penalty is 14 cycles. Branch mispredict rates depend on the workload. Using perf stat on a few different things (bzip2, top, mysqld, regenerating my blog), I get branch mispredict rates of between 0.5% and 4%. If we say that a correctly predicted branch costs 1 cycle, that's an average cost of between .995 * 1 + .005 * 14 = 1.065 cycles to .96 * 1 + .04 * 14 = 1.52 cycles. That's not so bad.
This actually overstates the penalty since about 1995, since Intel added conditional move instructions that allow you to conditionally move data without a branch. This instruction was memorably panned by Linus, which has given it a bad reputation, but it's fairly common to get significant speedups using cmov compared to branches
A real-world example of the cost of extra branches are enabling integer overflow checks. When using bzip2 to compress a particular file, that increases the number of instructions by about 30% (with all of the increase coming from extra branch instructions), which results in a 1% performance hit.
Unpredictable branches are bad, but most branches are predictable. Ignoring the cost of branches until your profiler tells you that you have a hot spot is pretty reasonable nowadays. CPUs have gotten a lot better at executing poorly optimized code over the past decade, and compilers are getting better at optimizing code, which makes optimizing branches a poor use of time unless you're trying to squeeze out the absolute best possible performance out of some code.
If it turns out that's what you need to do, you're likely to be better off using profile-guided optimization than trying to screw with this stuff by hand.
If you really must do this by hand, there are compiler directives you can use to say whether a particular branch is likely to be taken or not. Modern CPUs ignore branch hint instructions, but they can help the compiler lay out code better.
Alignment
Old school conventional wisdom is that you should pad out structs and make sure things are aligned. But on a Haswell chip, the mis-alignment for almost any single-threaded thing you can think of that doesn't cross a page boundary is zero. There are some cases where it can make a difference, but in general, this is another type of optimization that's mostly irrelevant because CPUs have gotten so much better at executing bad code. It's also mildly harmful in cases where it increases the memory footprint for no benefit.
Also, don't make things page aligned or otherwise aligned to large boundaries or you'll destroy the performance of your caches.
Self-modifying code
Here's another optimization that doesn't really make sense anymore. Using self-modifying code to decrease code size or increase performance used to make sense, but because modern caches tend to split up their l1 instruction and data caches, modifying running code requires expensive communication between a chip's l1 caches.
The Future
Here are some possible changes, from least speculative to most speculative.
Partitioning
It's now obvious that more and more compute is moving into large datacenters. Sometimes this involves running on VMs, sometimes it involves running in some kind of container, and sometimes it involves running bare metal, but in any case, individual machines are often multiplexed to run a wide variety of workloads. Ideally, you'd be able to schedule best effort workloads to soak up stranded resources without effecting latency sensitive workloads with an SLA. It turns out that you can actually do this with some relatively straightforward hardware changes.
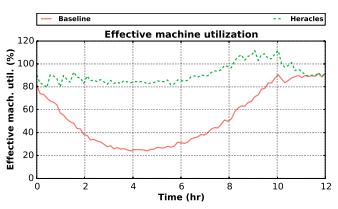
David Lo, et. al, were able to show that you can get about 90% machine utilization without impacting latency SLAs if caches can be partitioned such that best effort workloads don't impact latency sensitive workloads. The solid red line is the load on a normal Google web search cluster, and the dashed green line is what you get with the appropriate optimizations. From bar-room conversations, my impression is that the solid red line is actually already better (higher) than most of Google's competitors are able to do. If you compare the 90% optimized utilization to typical server utilization of 10% to 90%, that results in a massive difference in cost per unit of work compared to running a naive, unoptimized, setup. With substantial hardware effort, Google was able to avoid interference, but additional isolation features could allow this to be done at higher efficiency with less effort.
Transactional Memory and Hardware Lock Elision
IBM already has these features in their POWER chips. Intel made an attempt to add these to Haswell, but they're disabled because of a bug. In general, modern CPUs are quite complex and we should expect to see many more bugs than we used to.
Transactional memory support is what it sounds like: hardware support for transactions. This is through three new instructions, xbegin, xend, and xabort.
xbegin starts a new transaction. A conflict (or an xabort) causes the architectural state of the processor (including memory) to get rolled back to the state it was in just prior to the xbegin. If you're using transactional memory via library or language support, this should be transparent to you. If you're implementing the library support, you'll have to figure out how to convert this hardware support, with its limited hardware buffer sizes, to something that will handle arbitrary transactions.
I'm not going to discuss Hardware Lock Elision except to say that, under the hood, it's implemented with mechanisms that are really similar to the mechanisms used to implement transactional memory and that it's designed to speed up lock-based code. If you want to take advantage of HLE, see this doc.
Fast I/O
I/O bandwidth is going up and I/O latencies are going down, both for storage and for networking. The problem is that I/O is normally done via syscalls. As we've seen, the relative overhead of syscalls has been going up. For both storage and networking, the answer is to move to user mode I/O stacks (putting everything in kernel mode would work, too, but that's a harder sell). On the storage side, that's mostly still a weirdo research thing, but HPC and HFT folks have been doing that in networking for a while. And by a while, I don't mean a few months. Here's a paper from 2005 that talks about the networking stuff I'm going to discuss, as well as some stuff I'm not going to discuss (DCA).
This is finally trickling into the non-supercomputing world. MS has been advertising Azure with infiniband networking with virtualized RDMA for over a year, Cloudflare has talked about using Solarflare NICs to get the same capability, etc. Eventually, we're going to see SoCs with fast Ethernet onboard, and unless that's limited to Xeon-type devices, it's going to trick down into all devices. The competition between ARM devices will probably cause at least one ARM device maker to put fast Ethernet on their commodity SoCs, which may force Intel's hand.
That RDMA bit is significant; it lets you bypass the CPU completely and have the NIC respond to remote requests. A couple months ago, I worked through the Stanford/Coursera Mining Massive Data Sets class. During one of the first lectures, they provide an example of a “typical” datacenter setup with 1Gb top-of-rack switches. That's not unreasonable for processing “massive” data if you're doing kernel TCP through non-RDMA NICs, since you can floor an entire core trying to push 1Gb/s through linux's TCP stack. But with Azure, MS talks about getting 40Gb out of a single machine; that's one machine getting 40x the bandwidth of what you might expect out of an entire rack. They also mention sub 2 us latencies, which is multiple orders of magnitude lower than you can get out of kernel TCP. This isn't exactly a new idea. This paper from 2011 predicts everything that's happened on the network side so far, along with some things that are still a ways off.
This MS talk discusses how you can take advantage of this kind of bandwidth and latency for network storage. A concrete example that doesn't require clicking through to a link is Amazon's EBS. It lets you use an “elastic” disk of arbitrary size on any of your AWS nodes. Since a spinning metal disk seek has higher latency than an RPC over kernel TCP, you can get infinite storage pretty much transparently. For example, say you can get 100us (.1ms) latency out of your network, and your disk seek time is 8ms. That makes a remote disk access 8.1ms instead of 8ms, which isn't that much overhead. That doesn't work so well with SSDs, though, since you can get 20 us (.02ms) out of an SSD. But RDMA latency is low enough that a transparent EBS-like layer is possible for SSDs.
So that's networked I/O. The performance benefit might be even bigger on the disk side, if/when next generation storage technologies that are faster than flash start getting deployed. The performance delta is so large that Intel is adding new instructions to keep up with next generation low-latency storage technology. Depending on who you ask, that stuff has been a few years away for a decade or two; this is more iffy than the networking stuff. But even with flash, people are showing off devices that can get down into the single microsecond range for latency, which is a substantial improvement.
Hardware Acceleration
Like fast networked I/O, this is already here in some niches. DESRES has been doing ASICs to get 100x-1000x speedup in computational chemistry for years. Microsoft has talked about speeding up search with FPGAs. People have been looking into accelerating memcached and similar systems for a while, researchers from Toshiba and Stanford demonstrated a real implementation a while back, and I recently saw a pre-print out of Berkeley on the same thing. There are multiple companies making Bitcoin mining ASICs. That's also true for other application areas.
It seems like we should see more of this as it gets harder to get power/performance gains out of CPUs. You might consider this a dodge of your question, if you think of programming as being a software oriented endeavor, but another way to look at it is that what it means to program something will change. In the future, it might mean designing hardware like an FPGA or ASIC in combination with writing software.
Update
Now that it's 2016, one year after this post was originally published, we can see that companies are investing in hardware accelerators. In addition to its previous work on FPGA accelerated search, Microsoft has announced that it's using FPGAs to accelerate networking. Google has been closed mouthed about infrastructure, as is typical for them, but if you look at the initial release of Tensorflow, you can see snippets of code that clearly references FPGAs, such as:
enum class PlatformKind {
kInvalid,
kCuda,
kOpenCL,
kOpenCLAltera, // Altera FPGA OpenCL platform.
// See documentation: go/fpgaopencl
// (StreamExecutor integration)
kHost,
kMock,
kSize,
};
and
string PlatformKindString(PlatformKind kind) {
switch (kind) {
case PlatformKind::kCuda:
return "CUDA";
case PlatformKind::kOpenCL:
return "OpenCL";
case PlatformKind::kOpenCLAltera:
return "OpenCL+Altera";
case PlatformKind::kHost:
return "Host";
case PlatformKind::kMock:
return "Mock";
default:
return port::StrCat("InvalidPlatformKind(", static_cast<int>(kind), ")");
}
}
As of this writing, Google doesn't return any results for +google +kOpenClAltera, so it doesn't appear that this has been widely observed. If you're not familiar with Altera OpenCL and you work at google, you can try the internal go link suggested in the comment, go/fpgaopencl. If, like me, you don't work at Google, well, there's Altera's docs here. The basic idea is that you can take OpenCL code, the same kind of thing you might run on a GPU, and run it on an FPGA instead, and from the comment, it seems like Google has some kind of setup that lets you stream data in and out of nodes with FPGAs.
That FPGA-specific code was removed in ddd4aaf5286de24ba70402ee0ec8b836d3aed8c7, which has a commit message that starts with “TensorFlow: upstream changes to git.” and then has a list of internal google commits that are being upstreamed, along with a description of each internal commit. Curiously, there's nothing about removing FPGA support even though that seems like it's a major enough thing that you'd expect it to be described, unless it was purposely redacted. Amazon has also been quite secretive about their infrastructure plans, but you can make reasonable guesses there by looking at the hardware people they've been vacuuming up. A couple other companies are also betting pretty heavily on hardware accelerators, but since I learned about that through private conversations (as opposed to accidentally published public source code or other public information), I'll leave you to guess which companies.
Dark Silicon / SoCs
One funny side effect of the way transistor scaling has turned out is that we can pack a ton of transistors on a chip, but they generate so much heat that the average transistor can't switch most of the time if you don't want your chip to melt.
A result of this is that it makes more sense to include dedicated hardware that isn't used a lot of the time. For one thing, this means we get all sorts of specialized instructions like the PCMP and ADX instructions. But it also means that we're getting chips with entire devices integrated that would have previously lived off-chip. That includes things like GPUs and (for mobile devices) radios.
In combination with the hardware acceleration trend, it also means that it makes more sense for companies to design their own chips, or at least parts of their own chips. Apple has gotten a lot of mileage out of acquiring PA Semi. First, by adding little custom accelerators to bog standard ARM architectures, and then by adding custom accelerators to their own custom architecture. Due to a combination of the right custom hardware plus well thought out benchmarking and system design, the iPhone 4 is slightly more responsive than my flagship Android phone, which is multiple years newer and has a much faster processor as well as more RAM.
Amazon has picked up a decent chunk of the old Calxeda team and are hiring enough to create a good-sized hardware design team. Facebook has picked up a small handful of ARM SoC folks and is partnering with Qualcomm on something-or-other. Linus is on record as saying we're going to see more dedicated hardware all over the place. And so on and so forth.
Conclusion
x86 chips have picked up a lot of new features and whiz-bang gadgets. For the most part, you don't have to know what they are to take advantage of them. As a first-order approximation, making your code predictable and keeping memory locality in mind works pretty well. The really low-level stuff is usually hidden by libraries or drivers, and compilers will try to take care of the rest of it. The exceptions are if you're writing really low-level code, in which case the world has gotten a lot messier, or if you're trying to get the absolute best possible performance out of your code, in which case the world has gotten a lot weirder.
Also, things will happen in the future. But most predictions are wrong, so who knows?
Resources
This is a talk by Matt Godbolt that covers a lot of the implementation details that I don't get into. To down into one more level of detail, see Modern Processor Design, by Shen and Lipasti. Despite the date listed on Amazon (2013), the book is pretty old, but it's still the best book I've found on processor internals. It describes, in good detail, what you need to implement to make a P6-era high-performance CPU. It also derives theoretical performance limits given different sets of assumptions and talks about a lot of different engineering tradeoffs, with explanations of why for a lot of them.
For one level deeper of "why", you'll probably need to look at a VLSI text, which will explain how devices and interconnect scale and how that affects circuit design, which in turn affects architecture. I really like Weste & Harris because they have clear explanations and good exercises with solutions that you can find online, but if you're not going to work the problems pretty much any VLSI text will do. For one more level deeper of the "why" of things, you'll want a solid state devices text and something that explains how transmission lines and interconnect can work. For devices, I really like Pierret's books. I got introduced to the E-mag stuff through Ramo, Whinnery & Van Duzer, but Ida is a better intro text.
For specifics about current generation CPUs and specific optimization techniques, see Agner Fog's site. For something on optimization tools from the future, see this post. What Every Programmer Should Know About Memory is also good background knowledge. Those docs cover a lot of important material, but if you're writing in a higher level language there are a lot of other things you need to keep in mind. For more on Intel CPU history, Xao-Feng Li has a nice overview.
For something a bit off the wall, see this post on the possibility of CPU backdoors. For something less off the wall, see this post on how complexity we have in modern CPUs enables all sorts of exciting bugs.
For more benchmarks on locking, See this post by Aleksey Shipilev, this post by Paul Khuong, as well as their archives.
For general benchmarking, last year's Strange Loop benchmarking talk by Aysylu Greenberg is a nice intro to common gotchas. For something more advanced but more specific, Gil Tene's talk on latency is great.
For historical computing that predates everything I've mentioned by quite some time, see IBM's Early Computers and Design of a Computer, which describes the design of the CDC 6600. Readings in Computer Architecture is also good for seeing where a lot of these ideas originally came from.
Sorry, this list is pretty incomplete. Suggestions welcome!
Tiny Disclaimer
I have no doubt that I'm leaving stuff out. Let me know if I'm leaving out anything you think is important and I'll update this. I've tried to keep things as simple as possible while still capturing the flavor of what's going on, but I'm sure that there are some cases where I'm oversimplifying, and some things that I just completely forgot to mention. And of course basically every generalization I've made is wrong if you're being really precise. Even just picking at my first couple sentences, A20M isn't always and everywhere irrelevant (I've probably spent about 0.2% of my career dealing with it), x86-64 isn't strictly superior to x86 (on one workload I had to deal with, the performance benefit from the extra registers was more than canceled out by the cost of the longer instructions; it's pretty rare that the instruction stream and icache misses are the long pole for a workload, but it happens), etc. The biggest offender is probably in my NUMA explanation, since it is actually possible for P6 busses to respond with a defer or retry to a request. It's reasonable to avoid using a similar mechanism to enforce coherency but I couldn't think of a reasonable explanation of why that didn't involve multiple levels of explanations. I'm really not kidding when I say that pretty much every generalization falls apart if you dig deep enough. Every abstraction I'm talking about is leaky. I've tried to include links to docs that go at least one level deeper, but I'm probably missing some areas.
Acknowledgments
Thanks to Leah Hanson and Nathan Kurz for comments that results in major edits, and to Nicholas Radcliffe, Stefan Kanthak, Garret Reid, Matt Godbolt, Nikos Patsiouras, Aleksey Shipilev, and Oscar R Moll for comments that resulted in minor edits, and to David Albert for allowing me to quote him and also for some interesting follow-up questions when we talked about this a while back. Also, thanks for Cliff Burdick for writing the section on GPUs and for Hari Angepat for spotting the Google kOpenCLAltera code in TensorFlow.