I was curious what different people worked on in Linux, so I tried grabbing data from the current git repository to see if I could pull that out of commit message data. This doesn't include history from before they switched to git, so it only goes back to 2005, but that's still a decent chunk of history.
Here's a list of the most commonly used words (in commit messages), by the top four most frequent committers, with users ordered by number of commits.
| User | 1 | 2 | 3 | 4 | 5 |
| viro | to | in | of | and | the |
| tiwai | alsa | the | - | for | to |
| broonie | the | to | asoc | for | a |
| davem | the | to | in | and | sparc64 |
Alright, so their most frequently used words are to, alsa, the, and the. Turns out, Takashi Iwai (tiwai) often works on audio (alsa), and by going down the list we can see that David Miller's (davem) fifth most frequently used term is sparc64, which is a pretty good indicator that he does a lot of sparc work. But the table is mostly noise. Of course people use to, in, and other common words all the time! Putting that into a table provides zero information.
There are a number of standard techniques for dealing with this. One is to explicitly filter out "stop words", common words that we don't care about. Unfortunately, that doesn't work well with this dataset without manual intervention. Standard stop-word lists are going to miss things like Signed-off-by and cc, which are pretty uninteresting. We can generate a custom list of stop words using some threshold for common words in commit messages, but any threshold high enough to catch all of the noise is also going to catch commonly used but interesting terms like null and driver.
Luckily, it only takes about a minute to do by hand. After doing that, the result is that many of the top words are the same for different committers. I won't reproduce the table of top words by committer because it's just many of the same words repeated many times. Instead, here's the table of the top words (ranked by number of commit messages that use the word, not raw count), with stop words removed, which has the same data without the extra noise of being broken up by committer.
| Word | Count |
| driver | 49442 |
| support | 43540 |
| function | 43116 |
| device | 32915 |
| arm | 28548 |
| error | 28297 |
| kernel | 23132 |
| struct | 18667 |
| warning | 17053 |
| memory | 16753 |
| update | 16088 |
| bit | 15793 |
| usb | 14906 |
| bug | 14873 |
| register | 14547 |
| avoid | 14302 |
| pointer | 13440 |
| problem | 13201 |
| x86 | 12717 |
| address | 12095 |
| null | 11555 |
| cpu | 11545 |
| core | 11038 |
| user | 11038 |
| media | 10857 |
| build | 10830 |
| missing | 10508 |
| path | 10334 |
| hardware | 10316 |
Ok, so there's been a lot of work on arm, lots of stuff related to memory, null, pointer, etc. But if want to see what individuals work on, we'll need something else.
That something else could be penalizing more common words without eliminating them entirely. A standard metric to normalize by is the inverse document frequency (IDF), log(# of messages / # of messages with word). So instead of ordering by term count or term frequency, let's try ordering by (term frequency) * log(# of messages / # of messages with word), which is commonly called TF-IDF. This gives us words that one person used that aren't commonly used by other people.
Here's a list of the top 40 linux committers and their most commonly used words, according to TF-IDF.
| User | 1 | 2 | 3 | 4 | 5 |
| viro | switch | annotations | patch | of | endianness |
| tiwai | alsa | hda | codec | codecs | hda-codec |
| broonie | asoc | regmap | mfd | regulator | wm8994 |
| davem | sparc64 | sparc | we | kill | fix |
| gregkh | cc | staging | usb | remove | hank |
| mchehab | v4l/dvb | media | at | were | em28xx |
| tglx | x86 | genirq | irq | prepare | shared |
| hsweeten | comedi | staging | tidy | remove | subdevice |
| mingo | x86 | sched | zijlstra | melo | peter |
| joe | unnecessary | checkpatch | convert | pr_ | use |
| tj | cgroup | doesnt | which | it | workqueue |
| lethal | sh | up | off | sh64 | kill |
| axel.lin | regulator | asoc | convert | thus | use |
| hch | xfs | sgi-pv | sgi-modid | remove | we |
| sachin.kamat | redundant | remove | simpler | null | of_match_ptr |
| bzolnier | ide | shtylyov | sergei | acked-by | caused |
| alan | tty | gma500 | we | up | et131x |
| ralf | mips | fix | build | ip27 | of |
| johannes.berg | mac80211 | iwlwifi | it | cfg80211 | iwlagn |
| trond.myklebust | nfs | nfsv4 | sunrpc | nfsv41 | ensure |
| shemminger | sky2 | net_device_ops | skge | convert | bridge |
| bunk | static | needlessly | global | patch | make |
| hartleys | comedi | staging | remove | subdevice | driver |
| jg1.han | simpler | device_release | unnecessary | clears | thus |
| akpm | cc | warning | fix | function | patch |
| rmk+kernel | arm | acked-by | rather | tested-by | we |
| daniel.vetter | drm/i915 | reviewed-by | v2 | wilson | vetter |
| bskeggs | drm/nouveau | drm/nv50 | drm/nvd0/disp | on | chipsets |
| acme | galbraith | perf | weisbecker | eranian | stephane |
| khali | hwmon | i2c | driver | drivers | so |
| torvalds | linux | commit | just | revert | cc |
| chris | drm/i915 | we | gpu | bugzilla | whilst |
| neilb | md | array | so | that | we |
| lars | asoc | driver | iio | dapm | of |
| kaber | netfilter | conntrack | net_sched | nf_conntrack | fix |
| dhowells | keys | rather | key | that | uapi |
| heiko.carstens | s390 | since | call | of | fix |
| ebiederm | namespace | userns | hallyn | serge | sysctl |
| hverkuil | v4l/dvb | ivtv | media | v4l2 | convert |
That's more like it. Some common words still appear -- this would really be improved with manual stop words to remove things like cc and of. But for the most part, we can see who works on what. Takashi Iwai (tiwai) spends a lot of time in hda land and workig on codecs, David S. Miller (davem) has spent a lot of time on sparc64, Ralf Baechle (ralf) does a lot of work with mips, etc. And then again, maybe it's interesting that some, but not all, people cc other folks so much that it shows up in their top 5 list even after getting penalized by IDF.
We can also use this to see the distribution of what people talk about in their commit messages vs. how often they commit.
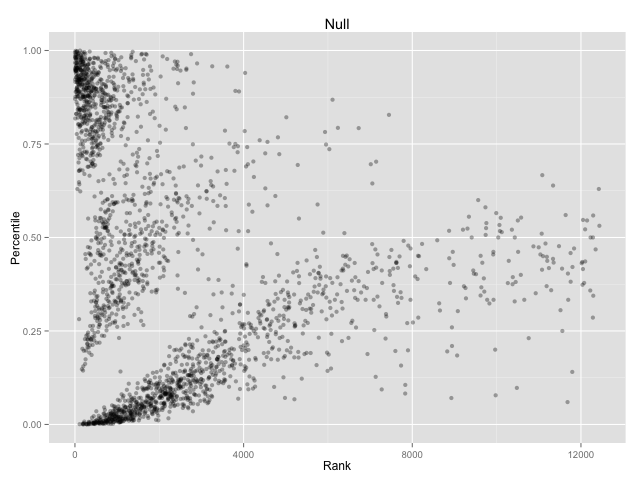
This graph has people on the x-axis and relative word usage (ranked by TF-IDF) y-axis. On the x-axis, the most frequent committers on the left and least frequent on the right. On the y-axis, points are higher up if that committer used the word null more frequently, and lower if the person used the word null less frequently.
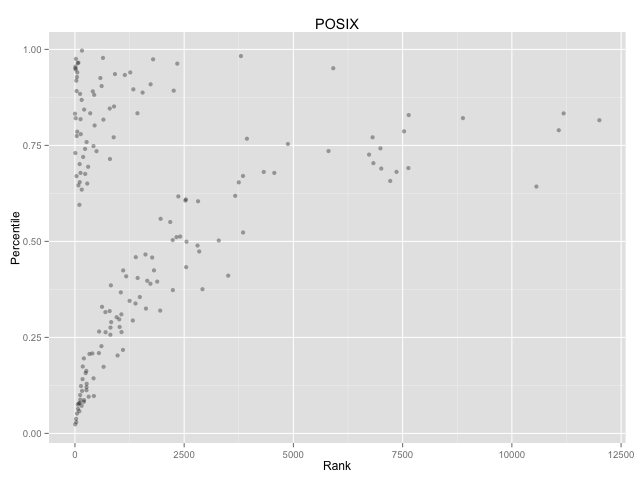
Relatively, almost no one works on POSIX compliance. You can actually count the individual people who mentioned POSIX in commit messages.
This is the point of the blog post where you might expect some kind of summary, or at least a vague point. Sorry. No such luck. I just did this because TF-IDF is one of a zillion concepts presented in the Mining Massive Data Sets course running now, and I knew it wouldn't really stick unless I wrote some code.
If you really must have a conclusion, TF-IDF is sometimes useful and incredibly easy to apply. You should use it when you should use it (when you want to see what words distinguish different documents/people from each other) and you shouldn't use it when you shouldn't use it (when you want to see what's common to documents/people). The end.
I'm experimenting with blogging more by spending less time per post and just spewing stuff out in 30-90 minute sitting. Please let me know if something is unclear or just plain wrong. Seriously. I went way over time on this one, but that's mostly because argh data and tables and bugs in Julia, not because of proofreading. I'm sure there are bugs!
Thanks to Leah Hanson for finding a bunch of writing bugs in this post and to Zack Maril for a conversation on how to maybe display change over time in the future.