Every once in awhile, you hear a story like “there was a case of a 1-Gbps NIC card on a machine that suddenly was transmitting only at 1 Kbps, which then caused a chain reaction upstream in such a way that the performance of the entire workload of a 100-node cluster was crawling at a snail's pace, effectively making the system unavailable for all practical purposes”. The stories are interesting and the postmortems are fun to read, but it's not really clear how vulnerable systems are to this kind of failure or how prevalent these failures are.
The situation reminds me of distributed systems failures before Jepsen. There are lots of anecdotal horror stories, but a common response to those is “works for me”, even when talking about systems that are now known to be fantastically broken. A handful of companies that are really serious about correctness have good tests and metrics, but they mostly don't talk about them publicly, and the general public has no easy way of figuring out if the systems they're running are sound.
Thanh Do et al. have tried to look at this systematically -- what's the effect of hardware that's been crippled but not killed, and how often does this happen in practice? It turns out that a lot of commonly used systems aren't robust against against “limping” hardware, but that the incidence of these types of failures are rare (at least until you have unreasonably large scale).
The effect of a single slow node can be quite dramatic:
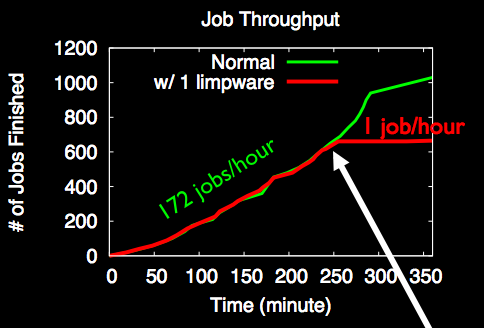
The job completion rate slowed down from 172 jobs per hour to 1 job per hour, effectively killing the entire cluster. Facebook has mechanisms to deal with dead machines, but they apparently didn't have any way to deal with slow machines at the time.
When Do et al. looked at widely used open source software (HDFS, Hadoop, ZooKeeper, Cassandra, and HBase), they found similar problems.
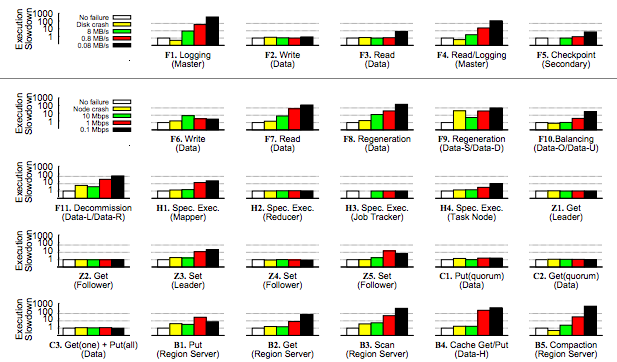
Each subgraph is a different failure condition. F is HDFS, H is Hadoop, Z is Zookeeper, C is Cassandra, and B is HBase. The leftmost (white) bar is the baseline no-failure case. Going to the right, the next is a crash, and the subsequent bars are results for a single degraded but not crashed hardware (further right means slower). In most (but not all) cases, having degraded hardware affected performance a lot more than having failed hardware. Note that these graphs are all log scale; going up one increment is a 10x difference in performance!
Curiously, a failed disk can cause some operations to speed up. That's because there are operations that have less replication overhead if a replica fails. It seems a bit weird to me that there isn't more overhead, because the system has to both find a replacement replica and replicate data, but what do I know?
Anyway, why is a slow node so much worse than a dead node? The authors define three failure modes and explain what causes each one. There's operation limplock, when an operation is slow because some subpart of the operation is slow (e.g., a disk read is slow because the disk is degraded), node limplock, when a node is slow even for seemingly unrelated operations (e.g, a read from RAM is slow because a disk is degraded), and cluster limplock, where the entire cluster is slow (e.g., a single degraded disk makes an entire 1000 machine cluster slow).
How do these happen?
Operation Limplock
This one is the simplest. If you try to read from disk, and your disk is slow, your disk read will be slow. In the real world, we'll see this when operations have a single point of failure, and when monitoring is designed to handle total failure and not degraded performance. For example, an HBase access to a region goes through the server responsible for that region. The data is replicated on HDFS, but this doesn't help you if the node that owns the data is limping. Speaking of HDFS, it has a timeout is 60s and reads are in 64K chunks, which means your reads can slow down to almost 1K/s before HDFS will fail over to a healthy node.
Node Limplock
How can it be the case that (for example) a slow disk causes memory reads to be slow? Looking at HDFS again, it uses a thread pool. If every thread is busy very slowly completing a disk read, memory reads will block until a thread gets free.
This isn't only an issue when using limited thread pools or other bounded abstractions -- the reality is that machines have finite resources, and unbounded abstractions will run into machine limits if they aren't carefully designed to avoid the possibility. For example, Zookeeper keeps queue of operations, and a slow follower can cause the leader's queue to exhaust physical memory.
Cluster Limplock
An entire cluster can easily become unhealthy if it relies on a single primary and the primary is limping. Cascading failures can also cause this -- the first graph, where a cluster goes from completing 172 jobs an hour to 1 job an hour is actually a Facebook workload on Hadoop. The thing that's surprising to me here is that Hadoop is supposed to be tail tolerant -- individual slow tasks aren't supposed to have a large impact on the completion of the entire job. So what happened? Unhealthy nodes infect healthy nodes and eventually lock up the whole cluster.
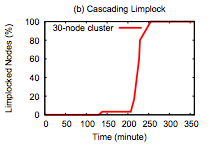
Hadoop's tail tolerance comes from kicking off speculative computation when results are coming in slowly. In particular, when stragglers come in unusually slowly compared to other results. This works fine when a reduce node is limping (subgraph H2), but when a map node limps (subgraph H1), it can slow down all reducers in the same job, which defeats Hadoop's tail-tolerance mechanisms.
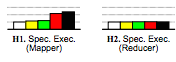
To see why, we have to look at Hadoop's speculation algorithm. Each job has a progress score which is a number between 0 and 1 (inclusive). For a map, the score is the fraction of input data read. For a reduce, each of three phases (copying data from mappers, sorting, and reducing) gets 1/3 of the score. A speculative job will get run if a task has run for at least one minute and has a progress score that's less than the average for its category minus 0.2.
In case H2, the NIC is limping, so the map phase completes normally since results end up written to local disk. But when reduce nodes try to fetch data from the limping map node, they all stall, pulling down the average score for the category, which prevents speculative jobs from being run. Looking at the big picture, each Hadoop node has a limited number of map and reduce tasks. If those fill up with limping tasks, the entire node will lock up. Since Hadoop isn't designed to avoid cascading failures, this eventually causes the entire cluster to lock up.
One thing I find interesting is that this exact cause of failures was described in the original MapReduce paper, published in 2004. They even explicitly called out slow disk and network as causes of stragglers, which motivated their speculative execution algorithm. However, they didn't provide the details of the algorithm. The open source clone of MapReduce, Hadoop, attempted to avoid the same problem. Hadoop was initially released in 2008. Five years later, when the paper we're reading was published, its built-in mechanism for straggler detection not only failed to prevent multiple types of stragglers, it also failed to prevent stragglers from effectively deadlocking the entire cluster.
Conclusion
I'm not going to go into details of how each system fared under testing. That's detailed quite nicely in the paper, which I recommend reading the paper if you're curious. To summarize, Cassandra does quite well, whereas HDFS, Hadoop, and HBase don't.
Cassandra seems to do well for two reasons. First, this patch from 2009 prevents queue overflows from infecting healthy nodes, which prevents a major failure mode that causes cluster-wide failures in other systems. Second, the architecture used (SEDA) decouples different types of operations, which lets good operations continue to execute even when some operations are limping.
My big questions after reading this paper are, how often do these kinds of failures happen, how, and shouldn't reasonable metrics/reporting catch this sort of thing anyway?
For the answer to the first question, many of the same authors also have a paper where they looked at 3000 failures in Cassandra, Flume, HDFS, and ZooKeeper and determined which failures were hardware related and what the hardware failure was.
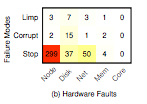
14 cases of degraded performance vs. 410 other hardware failures. In their sample, that's 3% of failures; rare, but not so rare that we can ignore the issue.
If we can't ignore these kinds of errors, how can we catch them before they go into production? The paper uses the Emulab testbed, which is really cool. Unfortunately, the Emulab page reads “Emulab is a public facility, available without charge to most researchers worldwide. If you are unsure if you qualify for use, please see our policies document, or ask us. If you think you qualify, you can apply to start a new project.”. That's understandable, but that means it's probably not a great solution for most of us.
The vast majority of limping hardware is due to network or disk slowness. Why couldn't a modified version of Jepsen, or something like it, simulate disk or network slowness? A naive implementation wouldn't get anywhere near the precision of Emulab, but since we're talking about order of magnitude slowdowns, having 10% (or even 2x) variance should be ok for testing the robustness of systems against degraded hardware. There are a number of ways you could imagine that working. For example, to simulate a slow network on linux, you could try throttling via qdisc, hooking syscalls via ptrace, etc. For a slow CPU, you can rate-limit via cgroups and cpu.shares, or just map the process to UC memory (or maybe WT or WC if that's a bit too slow), and so on and so forth for disk and other failure modes.
That leaves my last question, shouldn't systems already catch these sorts of failures even if they're not concerned about them in particular? As we saw above, systems with cripplingly slow hardware are rare enough that we can just treat them as dead without significantly impacting our total compute resources. And systems with crippled hardware can be detected pretty straightforwardly. Moreover, multi-tenant systems have to do continuous monitoring of their own performance to get good utilization anyway.
So why should we care about designing systems that are robust against limping hardware? One part of the answer is defense in depth. Of course we should have monitoring, but we should also have systems that are robust when our monitoring fails, as it inevitably will. Another part of the answer is that by making systems more tolerant to limping hardware, we'll also make them more tolerant to interference from other workloads in a multi-tenant environment. That last bit is a somewhat speculative empirical question -- it's possible that it's more efficient to design systems that aren't particularly robust against interference from competing work on the same machine, while using better partitioning to avoid interference.
Thanks to Leah Hanson, Hari Angepat, Laura Lindzey, Julia Evans, and James M. Lee for comments/discussion.