The latest version of the Intel manual has a couple of new instructions for non-volatile storage, like SSDs. What's that about?
Before we look at the instructions in detail, let's take a look at the issues that exist with super fast NVRAM. One problem is that next generation storage technologies (PCM, 3d XPoint, etc.), will be fast enough that syscall and other OS overhead can be more expensive than the actual cost of the disk access. Another is the impedance mismatch between the x86 memory hierarchy and persistent memory. In both cases, it's basically an Amdahl's law problem, where one component has improved so much that other components have to improve to keep up.
There's a good paper by Todor Mollov, Louis Eisner, Arup De, Joel Coburn, and Steven Swanson on the first issue; I'm going to present one of their graphs below.
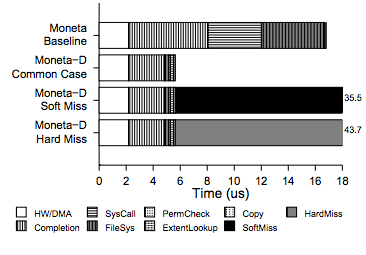
Everything says “Moneta” because that's the name of their system (which is pretty cool, BTW; I recommend reading the paper to see how they did it). Their “baseline” case is significantly better than you'll get out of a stock system. They did a number of optimizations (e.g., bypassing Linux's IO scheduler and removing context switches where possible), which reduces latency by 62% over plain old linux. Despite that, the hardware + DMA cost of the transaction (the white part of the bar) is dwarfed by the overhead. Note that they consider the cost of the DMA to be part of the hardware overhead.
They're able to bypass the OS entirely and reduce a lot of the overhead, but it's still true that the majority of the cost of a write is overhead.
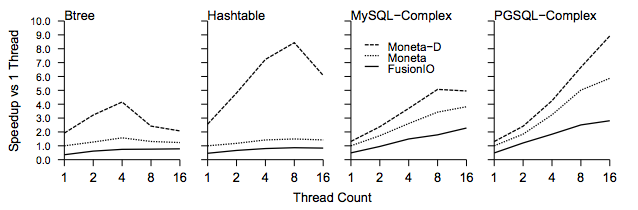
Despite not being able to get rid of all of the overhead, they get pretty significant speedups, both on small microbenchmarks and real code. So that's one problem. The OS imposes a pretty large tax on I/O when your I/O device is really fast.
Maybe you can bypass large parts of that problem by just mapping your NVRAM device to a region of memory and committing things to it as necessary. But that runs into another problem. which is the impedance mismatch between how caches interact with the NVRAM region if you want something like transactional semantics.
This is described in more detail in this report by Kumud Bhandari, Dhruva R. Chakrabarti, and Hans-J. Boehm. I'm going to borrow a couple of their figures, too.
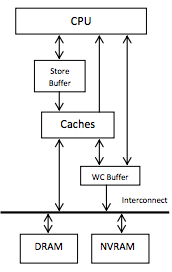
We've got this NVRAM region which is safe and persistent, but before the CPU can get to it, it has to go through multiple layers with varying ordering guarantees. They give the following example:
Consider, for example, a common programming idiom where a persistent memory location N is allocated, initialized, and published by assigning the allocated address to a global persistent pointer p. If the assignment to the global pointer becomes visible in NVRAM before the initialization (presumably because the latter is cached and has not made its way to NVRAM) and the program crashes at that very point, a post-restart dereference of the persistent pointer will read uninitialized data. Assuming writeback (WB) caching mode, this can be avoided by inserting cache-line flushes for the freshly allocated persistent locations N before the assignment to the global persistent pointer p.
Inserting CLFLUSH instructions all over the place works, but how much overhead is that?
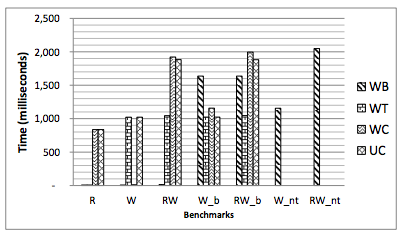
The four memory types they look at (and the four that x86 supports) are writeback (WB), writethrough (WT), write combine (WC), and uncacheable (UC). WB is what you deal with under normal circumstances. Memory can be cached and it's written back whenever it's forced to be. WT allows memory to be cached, but writes have to be written straight through to memory, i.e., memory is kept up to date with the cache. UC simply can't be cached. WC is like UC, except that writes can be coalesced before being sent out to memory.
The R, W, and RW benchmarks are just benchmarks of reading and writing memory. WB is clearly the best, by far (lower is better). If you want to get an intuitive feel for how much better WB is than the other policies, try booting an OS with anything but WB memory.
I've had to do that on occasion because I use to work for a chip company, and when we first got the chip back, we often didn't know which bits we had to disable to work around bugs. The simplest way to make progress is often to disable caches entirely. That “works”, but even minimal OSes like DOS are noticeably slow to boot without WB memory. My recollection is that Win 3.1 takes the better part of an hour, and that Win 95 is a multiple hour process.
The _b benchmarks force writes to be visible to memory. For the WB case, that involves an MFENCE followed by a CLFLUSH. WB with visibility constraints is significantly slower than the other alternatives. It's a multiple order of magnitude slowdown over WB when writes don't have to be ordered and flushed.
They also run benchmarks on some real data structures, with the constraint that data should be persistently visible.
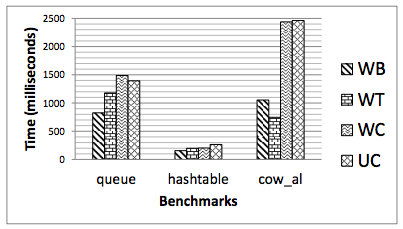
The performance of regular WB memory can be terribly slow: within a factor of 2 of the performance of running without caches. And that's just the overhead around getting out of the cache hierarchy -- that's true even if your persistent storage is infinitely fast.
Now, let's look how Intel decided to address this. There are two new instructions, CLWB and PCOMMIT.
CLWB acts like CLFLUSH, in that it forces the data to get written out to memory. However, it doesn't force the cache to throw away the data, which makes future reads and writes a lot faster. Also, CLFLUSH is only ordered with respect to MFENCE, but CLWB is also ordered with respect to SFENCE. Here's their description of CLWB:
Writes back to memory the cache line (if dirty) that contains the linear address specified with the memory operand from any level of the cache hierarchy in the cache coherence domain. The line may be retained in the cache hierarchy in non-modified state. Retaining the line in the cache hierarchy is a performance optimization (treated as a hint by hardware) to reduce the possibility of cache miss on a subsequent access. Hardware may choose to retain the line at any of the levels in the cache hierarchy, and in some cases, may invalidate the line from the cache hierarchy. The source operand is a byte memory location.
It should be noted that processors are free to speculatively fetch and cache data from system memory regions that are assigned a memory-type allowing for speculative reads (such as, the WB, WC, and WT memory types). Because this speculative fetching can occur at any time and is not tied to instruction execution, the CLWB instruction is not ordered with respect to PREFETCHh instructions or any of the speculative fetching mechanisms (that is, data can be speculatively loaded into a cache line just before, during, or after the execution of a CLWB instruction that references the cache line).
CLWB instruction is ordered only by store-fencing operations. For example, software can use an SFENCE, MFENCE, XCHG, or LOCK-prefixed instructions to ensure that previous stores are included in the write-back. CLWB instruction need not be ordered by another CLWB or CLFLUSHOPT instruction. CLWB is implicitly ordered with older stores executed by the logical processor to the same address.
Executions of CLWB interact with executions of PCOMMIT. The PCOMMIT instruction operates on certain store-to-memory operations that have been accepted to memory. CLWB executed for the same cache line as an older store causes the store to become accepted to memory when the CLWB execution becomes globally visible.
PCOMMIT is applied to entire memory ranges and ensures that everything in the memory range is committed to persistent storage. Here's their description of PCOMMIT:
The PCOMMIT instruction causes certain store-to-memory operations to persistent memory ranges to become persistent (power failure protected).1 Specifically, PCOMMIT applies to those stores that have been accepted to memory.
While all store-to-memory operations are eventually accepted to memory, the following items specify the actions software can take to ensure that they are accepted:
Non-temporal stores to write-back (WB) memory and all stores to uncacheable (UC), write-combining (WC), and write-through (WT) memory are accepted to memory as soon as they are globally visible. If, after an ordinary store to write-back (WB) memory becomes globally visible, CLFLUSH, CLFLUSHOPT, or CLWB is executed for the same cache line as the store, the store is accepted to memory when the CLFLUSH, CLFLUSHOPT or CLWB execution itself becomes globally visible.
If PCOMMIT is executed after a store to a persistent memory range is accepted to memory, the store becomes persistent when the PCOMMIT becomes globally visible. This implies that, if an execution of PCOMMIT is globally visible when a later store to persistent memory is executed, that store cannot become persistent before the stores to which the PCOMMIT applies.
The following items detail the ordering between PCOMMIT and other operations:
A logical processor does not ensure previous stores and executions of CLFLUSHOPT and CLWB (by that logical processor) are globally visible before commencing an execution of PCOMMIT. This implies that software must use appropriate fencing instruction (e.g., SFENCE) to ensure the previous stores-to-memory operations and CLFLUSHOPT and CLWB executions to persistent memory ranges are globally visible (so that they are accepted to memory), before executing PCOMMIT.
A logical processor does not ensure that an execution of PCOMMIT is globally visible before commencing subsequent stores. Software that requires that such stores not become globally visible before PCOMMIT (e.g., because the younger stores must not become persistent before those committed by PCOMMIT) can ensure by using an appropriate fencing instruction (e.g., SFENCE) between PCOMMIT and the later stores.
An execution of PCOMMIT is ordered with respect to executions of SFENCE, MFENCE, XCHG or LOCK-prefixed instructions, and serializing instructions (e.g., CPUID).
Executions of PCOMMIT are not ordered with respect to load operations. Software can use MFENCE to order loads with PCOMMIT.
Executions of PCOMMIT do not serialize the instruction stream.
How much CLWB and PCOMMIT actually improve performance will be up to their implementations. It will be interesting to benchmark these and see how they do. In any case, this is an attempt to solve the WB/NVRAM impedance mismatch issue. It doesn't directly address the OS overhead issue, but that can, to a large extent, be worked around without extra hardware.
If you liked this post, you'll probably also enjoy reading about cache partitioning in Broadwell and newer Intel server parts.
Thanks to Eric Bron for spotting this in the manual and pointing it out, and to Leah Hanson, Nate Rowe, and 'unwind' for finding typos.
If you haven't had enough of papers, Zvonimir Bandic pointed out a paper by Dejan Vučinić, Qingbo Wang, Cyril Guyot, Robert Mateescu, Filip Blagojević, Luiz Franca-Neto, Damien Le Moal, Trevor Bunker, Jian Xu, and Steven Swanson on getting 1.4 us latency and 700k IOPS out of a type of NVRAM
If you liked this post, you might also like this related post on "new" CPU features.