There've been regular viral stories about ML/AI bias with LLMs and generative AI for the past couple years. One thing I find interesting about discussions of bias is how different the reaction is in the LLM and generative AI case when compared to "classical" bugs in cases where there's a clear bug. In particular, if you look at forums or other discussions with lay people, people frequently deny that a model which produces output that's sort of the opposite of what the user asked for is even a bug. For example, a year ago, an Asian MIT grad student asked Playground AI (PAI) to "Give the girl from the original photo a professional linkedin profile photo" and PAI converted her face to a white face with blue eyes.
The top "there's no bias" response on the front-page reddit story, and one of the top overall comments, was
Sure, now go to the most popular Stable Diffusion model website and look at the images on the front page.
You'll see an absurd number of asian women (almost 50% of the non-anime models are represented by them) to the point where you'd assume being asian is a desired trait.
How is that less relevant that "one woman typed a dumb prompt into a website and they generated a white woman"?
Also keep in mind that she typed "Linkedin", so anyone familiar with how prompts currently work know it's more likely that the AI searched for the average linkedin woman, not what it thinks is a professional women because image AI doesn't have an opinion.
In short, this is just an AI ragebait article.
Other highly-ranked comments with the same theme include
Honestly this should be higher up. If you want to use SD with a checkpoint right now, if you dont [sic] want an asian girl it’s much harder. Many many models are trained on anime or Asian women.
and
Right? AI images even have the opposite problem. The sheer number of Asians in the training sets, and the sheer number of models being created in Asia, means that many, many models are biased towards Asian outputs.
Other highly-ranked comments noted that this was a sample size issue
"Evidence of systemic racial bias"
Shows one result.
Playground AI's CEO went with the same response when asked for an interview by the Boston Globe — he declined the interview and replied with a list of rhetorical questions like the following (the Boston Globe implies that there was more, but didn't print the rest of the reply):
If I roll a dice just once and get the number 1, does that mean I will always get the number 1? Should I conclude based on a single observation that the dice is biased to the number 1 and was trained to be predisposed to rolling a 1?
We could just have easily picked an example from Google or Facebook or Microsoft or any other company that's deploying a lot of ML today, but since the CEO of Playground AI is basically asking someone to take a look at PAI's output, we're looking at PAI in this post. I tried the same prompt the MIT grad student used on my Mastodon profile photo, substituting "man" for "girl". PAI usually turns my Asian face into a white (caucasian) face, but sometimes makes me somewhat whiter but ethnically ambiguous (maybe a bit Middle Eastern or East Asian or something. And, BTW, my face has a number of distinctively Vietnamese features and which pretty obviously look Vietnamese and not any kind of East Asian.



My profile photo is a light-skinned winter photo, so I tried a darker-skinned summer photo and PAI would then generally turn my face into a South Asian or African face, with the occasional Chinese (but never Vietnamese or kind of Southeast Asian face), such as the following:


A number of other people also tried various prompts and they also got results that indicated that the model (where “model” is being used colloquially for the model and its weights and any system around the model that's responsible for the output being what it is) has some preconceptions about things like what ethnicity someone has if they have a specific profession that are strong enough to override the input photo. For example, converting a light-skinned Asian person to a white person because the model has "decided" it can make someone more professional by throwing out their Asian features and making them white.
Other people have tried various prompts to see what kind of pre-conceptions are bundled into the model and have found similar results, e.g., Rob Ricci got the following results when asking for "linkedin profile picture of X professor" for "computer science", "philosophy", "chemistry", "biology", "veterinary science", "nursing", "gender studies", "Chinese history", and "African literature", respectively. In the 28 images generated for the first 7 prompts, maybe 1 or 2 people out of 28 aren't white. The results for the next prompt, "Chinese history" are wildly over-the-top stereotypical, something we frequently see from other models as well when asking for non-white output. And Andreas Thienemann points out that, except for the over-the-top Chinese stereotypes, every professor is wearing glasses, another classic stereotype.



Like I said, I don't mean to pick on Playground AI in particular. As I've noted elsewhere, trillion dollar companies regularly ship AI models to production without even the most basic checks on bias; when I tried ChatGPT out, every bias-checking prompt I played with returned results that were analogous to the images we saw here, e.g., when I tried asking for bios of men and women who work in tech, women tended to have bios indicating that they did diversity work, even for women who had no public record of doing diversity work and men tended to have degrees from name-brand engineering schools like MIT and Berkeley, even people who hadn't attended any name-brand schools, and likewise for name-brand tech companies (the link only has 4 examples due to Twitter limitations, but other examples I tried were consistent with the examples shown).
This post could've used almost any publicly available generative AI. It just happens to use Playground AI because the CEO's response both asks us to do it and reflects the standard reflexive "AI isn't biased" responses that lay people commonly give.
Coming back to the response about how it's not biased for professional photos of people to be turned white because Asians feature so heavily in other cases, the high-ranking reddit comment we looked at earlier suggested "go[ing] to the most popular Stable Diffusion model website and look[ing] at the images on the front page". Below is what I got when I clicked the link on the day the comment was made and then clicked "feed".
[Click to expand / collapse mildly NSFW images]
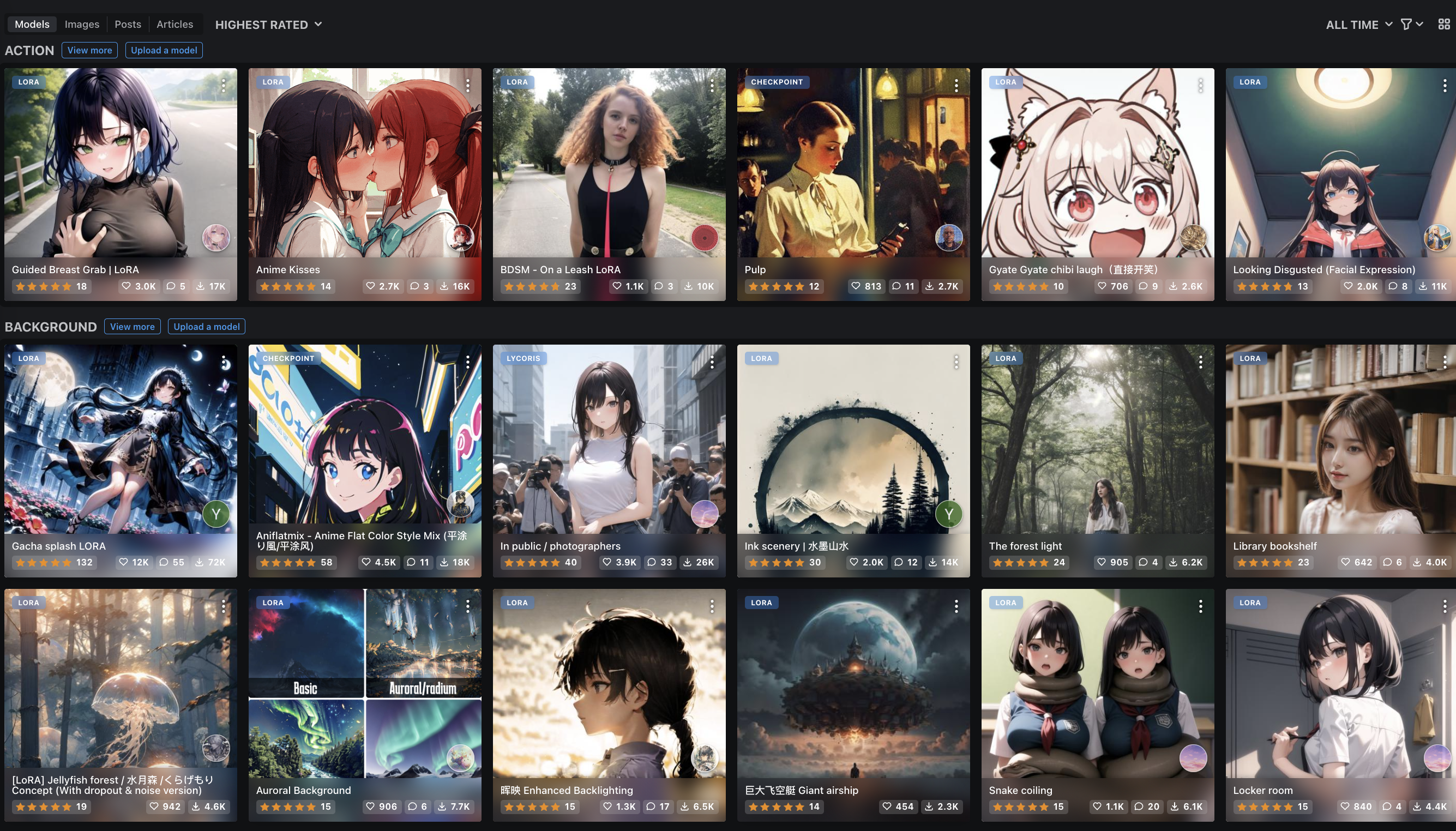

The site had a bit of a smutty feel to it. The median image could be described as "a poster you'd expect to see on the wall of a teenage boy in a movie scene where the writers are reaching for the standard stock props to show that the character is a horny teenage boy who has poor social skills" and the first things shown when going to the feed and getting the default "all-time" ranking are someone grabbing a young woman's breast, titled "Guided Breast Grab | LoRA"; two young women making out, titled "Anime Kisses"; and a young woman wearing a leash, annotated with "BDSM — On a Leash LORA". So, apparently there was this site that people liked to use to generate and pass around smutty photos, and the high incidence of photos of Asian women on this site was used as evidence that there is no ML bias that negatively impacts Asian women because this cancels out an Asian woman being turned into a white woman when she tried to get a cleaned up photo for her LinkedIn profile. I'm not really sure what to say to this. Fabian Geisen responded with "🤦♂️. truly 'I'm not bias. your bias' level discourse", which feels like an appropriate response.
Another standard line of reasoning on display in the comments, that I see in basically every discussion on AI bias, is typified by
AI trained on stock photo of “professionals” makes her white. Are we surprised?
She asked the AI to make her headshot more professional. Most of “professional” stock photos on the internet have white people in them.
and
If she asked her photo to be made more anything it would likely turn her white just because that’s the average photo in the west where Asians only make up 7.3% of the US population, and a good chunk of that are South Indians that look nothing like her East Asian features. East Asians are 5% or less; there’s just not much training data.
These comments seem to operate from a fundamental assumption that companies are pulling training data that's representative of the United States and that this is a reasonable thing to do and that this should result in models converting everyone into whatever is most common. This is wrong on multiple levels.
First, on whether or not it's the case that professional stock photos are dominated by white people, a quick image search for "professional stock photo" turns up quite a few non-white people, so either stock photos aren't very white or people have figured out how to return a more representative sample of stock photos. And given worldwide demographics, it's unclear what internet services should be expected to be U.S.-centric. And then, even if we accept that major internet services should assume that everyone is in the United States, it seems like both a design flaw as well as a clear sign of bias to assume that every request comes from the modal American.
Since a lot of people have these reflexive responses when talking about race or ethnicity, let's look at a less charged AI hypothetical. Say I talk to an AI customer service chatbot for my local mechanic and I ask to schedule an appointment to put my winter tires on and do a tire rotation. Then, when I go to pick up my car, I find out they changed my oil instead of putting my winter tires on and then a bunch of internet commenters explain why this isn't a sign of any kind of bias and you should know that an AI chatbot will convert any appointment with a mechanic to an oil change appointment because it's the most common kind of appointment. A chatbot that converts any kind of appointment request into "give me the most common kind of appointment" is pretty obviously broken but, for some reason, AI apologists insist this is fine when it comes to things like changing someone's race or ethnicity. Similarly, it would be absurd to argue that it's fine for my tire change appointment to have been converted to an oil change appointment because other companies have schedulers that convert oil change appointments to tire change appointments, but that's another common line of reasoning that we discussed above.
And say I used some standard non-AI scheduling software like Mindbody or JaneApp to schedule an appointment with my mechanic and asked for an appointment to have my tires changed and rotated. If I ended up having my oil changed because the software simply schedules the most common kind of appointment, this would be a clear sign that the software is buggy and no reasonable person would argue that zero effort should go into fixing this bug. And yet, this is a common argument that people are making with respect to AI (it's probably the most common defense in comments on this topic). The argument goes a bit further, in that there's this explanation of why the bug occurs that's used to justify why the bug should exist and people shouldn't even attempt to fix it. Such an explanation would read as obviously ridiculous for a "classical" software bug and is no less ridiculous when it comes to ML. Perhaps one can argue that the bug is much more difficult to fix in ML and that it's not practical to fix the bug, but that's different from the common argument that it isn't a bug and that this is the correct way for software to behave.
I could imagine some users saying something like that when the program is taking actions that are more opaque to the user, such as with autocorrect, but I actually tried searching reddit for autocorrect bug and in the top 3 threads (I didn't look at any other threads), 2 out of the 255 comments denied that incorrect autocorrects were a bug and both of those comments were from the same person. I'm sure if you dig through enough topics, you'll find ones where there's a higher rate, but on searching for a few more topics (like excel formatting and autocorrect bugs), none of the topics I searched approached what we see with generative AI, where it's not uncommon to see half the commenters vehemently deny that a prompt doing the opposite of what the user wants is a bug.
Coming back to the bug itself, in terms of the mechanism, one thing we can see in both classifiers as well as generative models is that many (perhaps most or almost all) of these systems are taking bias that a lot of people have that's reflected in some sample of the internet, which results in things like Google's image classifier classifying a black hand holding a thermometer as {hand, gun} and a white hand holding a thermometer as {hand, tool}. After a number of such errors over the past decade, from classifying black people as gorillas in Google Photos in 2015, to deploying some kind of text-classifier for ads that classified ads that contained the terms "African-American composers" and "African-American music" as "dangerous or derogatory" in 2018 Google turned the knob in the other direction with Gemini which, by the way, generated much more outrage than any of the other examples.
There's nothing new about bias making it into automated systems. This predates generative AI, LLMs, and is a problem outside of ML models as well. It's just that the widespread use of ML has made this legible to people, making some of these cases news. For example, if you look at compression algorithms and dictionaries, Brotli is heavily biased towards the English language — the human-language elements of the 120 transforms built into the language are English, and the built-in compression dictionary is more heavily weighted towards English than whatever representative weighting you might want to reference (population-weighted language speakers, non-automated human-languages text sent on on messaging platforms, etc.). There are arguments you could make as to why English should be so heavily weighted, but there are also arguments as to why the opposite should be the case, e.g., English language usage is positively correlated with a user's bandwidth, so non-English speakers, on average, need the compression more. But regardless of the exact weighting function you think should be used to generate a representative dictionary, that's just not going to make a viral news story because you can't get the typical reader to care that a number of the 120 built-in Brotli transforms do things like add " of the ", ". The", or ". This" to text, which are highly specialized for English, and none of the transforms encode terms that are highly specialized for any other human language even though only 20% of the world speaks English, or that, compared to the number of speakers, the built-in compression dictionary is extremely highly tilted towards English by comparison to any other human language. You could make a defense of the dictionary of Brotli that's analogous to the ones above, over some representative corpus which the Brotli dictionary was trained on, we get optimal compression with the Brotli dictionary, but there are quite a few curious phrases in the dictionary such as "World War II", ", Holy Roman Emperor", "British Columbia", "Archbishop" , "Cleveland", "esperanto", etc., that might lead us to wonder if the corpus the dictionary was trained on is perhaps not the most representative, or even particularly representative of text people send. Can it really be the case that including ", Holy Roman Emperor" in the dictionary produces, across the distribution of text sent on the internet, better compression than including anything at all for French, Urdu, Turkish, Tamil, Vietnamese, etc.?
Another example which doesn't make a good viral news story is my not being able to put my Vietnamese name in the title of my blog and have my blog indexed by Google outside of Vietnamese-language Google — I tried that when I started my blog and it caused my blog to immediately stop showing up in Google searches unless you were in Vietnam. It's just assumed that the default is that people want English language search results and, presumably, someone created a heuristic that would trigger if you have two characters with Vietnamese diacritics on a page that would effectively mark the page as too Asian and therefore not of interest to anyone in the world except in one country. "Being visibly Vietnamese" seems like a fairly common cause of bugs. For example, Vietnamese names are a problem even without diacritics. I often have forms that ask for my mother's maiden name. If I enter my mother's maiden name, I'll be told something like "Invalid name" or "Name too short". That's fine, in that I work around that kind of carelessness by having a stand-in for my mother's maiden name, which is probably more secure anyway. Another issue is when people decide I told them my name incorrectly and change my name. For my last name, if I read my name off as "Luu, ell you you", that gets shortened from the Vietnamese "Luu" to the Chinese "Lu" about half the time and to a western "Lou" much of the time as well, but I've figured out that if I say "Luu, ell you you, two yous", that works about 95% of the time. That sometimes annoys the person on the other end, who will exasperatedly say something like "you didn't have to spell it out three times". Maybe so for that particular person, but most people won't get it. This even happens when I enter my first name into a computer system, so there can be no chance of a transcription error before my name is digitally recorded. My legal first name, with no diacritics, is Dan. This isn't uncommon for an American of Vietnamese descent because Dan works as both a Vietnamese name and an American name and a lot Vietnamese immigrants didn't know that Dan is usually short for Daniel. At six of the companies I've worked for full-time, someone has helpfully changed my name to Daniel at three of them, presumably because someone saw that Dan was recorded in a database and decided that I failed to enter my name correctly and that they knew what my name was better than I did and they were so sure of this they saw no need to ask me about it. In one case, this only impacted my email display name. Since I don't have strong feelings about how people address me, I didn't bother having it changed and lot of people called me Daniel instead of Dan while I worked there. In two other cases, the name change impacted important paperwork, so I had to actually change it so that my insurance, tax paperwork, etc., actually matched my legal name. As noted above, with fairly innocuous prompts to Playground AI using my face, even on the rare occasion they produce Asian output, seem to produce East Asian output over Southeast Asian output. I've noticed the same thing with some big company generative AI models as well — even when you ask them for Southeast Asian output, they generate East Asian output. AI tools that are marketed as tools that clean up errors and noise will also clean up Asian-ness (and other analogous "errors"), e.g., people who've used Adobe AI noise reduction (billed as "remove noise from voice recordings with speech enhacement") note that it will take an Asian accent and remove it, making the person sound American (and likewise for a number of other accents, such as eastern European accents).
I probably see tens to hundreds things like this most weeks just in the course of using widely used software (much less than the overall bug count, which we previously observed was in hundreds to thousands per week), but most Americans I talk to don't notice these things at all. Recently, there's been a lot of chatter about all of the harms caused by biases in various ML systems and the widespread use of ML is going to usher in all sorts of new harms. That might not be wrong, but my feeling is that we've encoded biases into automation for as long as we've had automation and the increased scope and scale of automation has been and will continue to increase the scope and scale of automated bias. It's just that now, many uses of ML make these kinds of biases a lot more legible to lay people and therefore likely to make the news.
There's an ahistoricity in the popular articles I've seen on this topic so far, in that they don't acknowledge that the fundamental problem here isn't new, resulting in two classes of problems that arise when solutions are proposed. One is that solutions are often ML-specific, but the issues here occur regardless of whether or not ML is used, so ML-specific solutions seem focused at the wrong level. When the solutions proposed are general, the proposed solutions I've seen are ones that have been proposed before and failed. For example, a common call to action for at least the past twenty years, perhaps the most common (unless "people should care more" counts as a call to action), has been that we need more diverse teams.
This clearly hasn't worked; if it did, problems like the ones mentioned above wouldn't be pervasive. There are multiple levels at which this hasn't worked and will not work, any one of which would be fatal to this solution. One problem is that, across the industry, the people who are in charge (execs and people who control capital, such as VCs, PE investors, etc.), in aggregate, don't care about this. Although there are efficiency justifications for more diverse teams, the case will never be as clear-cut as it is for decisions in games and sports, where we've seen that very expensive and easily quantifiable bad decisions can persist for many decades after the errors were pointed out. And then, even if execs and capital were bought into the idea, it still wouldn't work because there are too many dimensions. If you look at a company that really prioritized diversity, like Patreon from 2013-2019, you're lucky if the organization is capable of seriously prioritizing diversity in two or three dimensions while dropping the ball on hundreds or thousands of other dimensions, such as whether or not Vietnamese names or faces are handled properly.
Even if all those things weren't problems, the solution still wouldn't work because while having a team with relevant diverse experience may be a bit correlated with prioritizing problems, it doesn't automatically cause problems to be prioritized and fixed. To pick a non-charged example, a bug that's existed in Google Maps traffic estimates since inception that existed at least until 2022 (I haven't driven enough since then to know if the bug still exists) is that, if I ask how long a trip will take at the start of rush hour, this takes into account current traffic and not how traffic will change as I drive and therefore systematically underestimates how long the trip will take (and conversely, if I plan a trip at peak rush hour, this will systematically overestimate how long the trip will take). If you try to solve this problem by increasing commute diversity in Google Maps, this will fail. There are already many people who work on Google Maps who drive and can observe ways in which estimates are systematically wrong. Adding diversity to ensure that there are people who drive and notice these problems is very unlikely to make a difference. Or, to pick another example, when the former manager of Uber's payments team got incorrected blacklisted from Uber by an ML model incorrectly labeling his transactions as fraudulent, no one was able to figure out what happened or what sort of bias caused him to get incorrectly banned (they solved the problem by adding his user to an allowlist). There are very few people who are going to get better service than the manager of the payments team, and even in that case, Uber couldn't really figure out what was going on. Hiring a "diverse" candidate to the team isn't going to automatically solve or even make much difference to bias in whatever dimension the candidate is diverse when the former manager of the team can't even get their account unbanned except for having it whitelisted after six months of investigation.
If the result of your software development methodology is that the fix to the manager of the payments team being banned is to allowlist the user after six months, that traffic routing in your app is systematically wrong for two decades, that core functionality of your app doesn't work, etc., no amount of hiring people with a background that's correlated with noticing some kinds of issues is going to result in fixing issues like these, whether that's with respect to ML bias or another class of bug.
Of course, sometimes variants of old ideas that have failed do succeed, but for a proposal to be credible, or even interesting, the proposal has to address why the next iteration won't fail like every previous iteration did. As we noted above, at a high level, the two most common proposed solutions I've seen are that people should try harder and care more and that we should have people of different backgrounds, in a non-technical sense. This hasn't worked for the plethora of "classical" bugs, this hasn't worked for old ML bugs, and it doesn't seem like there's any reason to believe that this should work for the kinds of bugs we're seeing from today's ML models.
Laurence Tratt says:
I think this is a more important point than individual instances of bias. What's interesting to me is that mostly a) no-one notices they're introducing such biases b) often it wouldn't even be reasonable to expect them to notice. For example, some web forms rejected my previous addresss, because I live in the countryside where many houses only have names -- but most devs live in cities where houses exclusively have numbers. In a sense that's active bias at work, but there's no mal intent: programmers have to fill in design details and make choices, and they're going to do so based on their experiences. None of us knows everything! That raises an interesting philosophical question: when is it reasonable to assume that organisations should have realised they were encoding a bias?
My feeling is that the "natural", as in lowest energy and most straightforward state for institutions and products is that they don't work very well. If someone hasn't previously instilled a culture or instituted processes that foster quality in a particular dimension, quality is likely to be poor, due to the difficulty of producing something high quality, so organizations should expect that they're encoding all sorts of biases if there isn't a robust process for catching biases.
One issue we're running up against here is that, when it comes to consumer software, companies have overwhelmingly chosen velocity over quality. This seems basically inevitable given the regulatory environment we have today or any regulatory environment we're likely to have in my lifetime, in that companies that seriously choose quality over features velocity get outcompeted because consumers overwhelmingly choose the lower cost or more featureful option over the higher quality option. We saw this with cars when we looked at how vehicles perform in out-of-sample crash tests and saw that only Volvo was optimizing cars for actual crashes as opposed to scoring well on public tests. Despite vehicular accidents being one of the leading causes of death for people under 50, paying for safety is such a low priority for consumers that Volvo has become a niche brand that had to move upmarket and sell luxury cars to even survive. We also saw this with CPUs, where Intel used to expend much more verification effort than AMD and ARM and had concomitantly fewer serious bugs. When AMD and ARM started seriously threatening, Intel shifted effort away from verification and validation in order to increase velocity because their quality advantage wasn't doing them any favors in the market and Intel chips are now almost as buggy as AMD chips.
We can observe something similar in almost every consumer market and many B2B markets as well, and that's when we're talking about issues that have known solutions. If we look at problem that, from a technical standpoint, we don't know how to solve well, like subtle or even not-so-subtle bias in ML models, it stands to reason that we should expect to see more and worse bugs than we'd expect out of "classical" software systems, which is what we're seeing. Any solution to this problem that's going to hold up in the market is going to have to be robust against the issue that consumers will overwhelmingly choose the buggier product if it has more features they want or ships features they want sooner, which puts any solution that requires taking care in a way that significantly slows down shipping in a very difficult position, absent a single dominant player, like Intel in its heyday.
Thanks to Laurence Tratt, Yossi Kreinin, Anonymous, Heath Borders, Benjamin Reeseman, Andreas Thienemann, and Misha Yagudin for comments/corrections/discussion
Appendix: technically, how hard is it to improve the situation?
This is a genuine question and not a rhetorical question. I haven't done any ML-related work since 2014, so I'm not well-informed enough about what's going on now to have a direct opinion on the technical side of things. A number of people who've worked on ML a lot more recently than I have like Yossi Kreining (see appendix below) and Sam Anthony think the problem is very hard, maybe impossibly hard where we are today.
Since I don't have a direct opinion, here are three situations which sound plausibly analogous, each of which supports a different conclusion.
Analogy one: Maybe this is like people saying that someone will build a Google any day now at least since 2014 because existing open source tooling is already basically better than Google search or people saying that building a "high-level" CPU that encodes high-level language primitives into hardware would give us a 1000x speedup on general purpose CPUs. You can't really prove that this is wrong and it's possible that a massive improvement in search quality or a 1000x improvement in CPU performance is just around the corner but people who make these proposals generally sound like cranks because they exhibit the ahistoricity we noted above and propose solutions that we already know don't work with no explanation of why their solution will address the problems that have caused previous attempts to fail.
Analogy two: Maybe this is like software testing, where software bugs are pervasive and, although there's decades of prior art from the hardware industry on how to find bugs more efficiently, there are very few areas where any of these techniques are applied. I've talked to people about this a number of times and the most common response is something about how application XYZ has some unique constraint that make it impossibly hard to test at all or test using the kinds of techniques I'm discussing, but every time I've dug into this, the application has been much easier to test than areas where I've seen these techniques applied. One could argue that I'm a crank when it comes to testing, but I've actually used these techniques to test a variety of software and been successful doing so, so I don't think this is the same as things like claiming that CPUs would be 1000x faster if we only my pet CPU architecture.
Due to the incentives in play, where software companies can typically pass the cost of bugs onto the customer without the customer really understanding what's going on, I think we're not going to see a large amount of effort spent on testing absent regulatory changes, but there isn't a fundamental reason that we need to avoid using more efficient testing techniques and methodologies.
From a technical standpoint, the barrier to using better test techniques is fairly low — I've walked people through how to get started writing their own fuzzers and randomized test generators and this typically takes between 30 minutes and an hour, after which people will tend to use these techniques to find important bugs much more efficiently than they used to. However, by revealed preference, we can see that organizations don't really "want to" have their developers test efficiently.
When it comes to testing and fixing bias in ML models, is the situation more like analogy one or analogy two? Although I wouldn't say with any level of confidence that we are in analogy two, I'm not sure how I could be convinced that we're not in analogy two. If I didn't know anything about testing, I would listen to all of these people explaining to me why their app can't be tested in a way that finds showstopping bugs and then conclude something like one of the following
- "Everyone" is right, which makes sense — this is a domain they know about and I don't, so why should I believe anything different?
- No opinion, perhaps on due to a high default level of skepticism
- Everyone is wrong, which seems unreasonable given that I don't know anything about the domain and have no particular reason to believe that everyone is wrong
As an outsider, it would take a very high degree of overconfidence to decide that everyone is wrong, so I'd have to either incorrectly conclude that "everyone" is right or have no opinion.
Given the situation with "classical" testing, I feel like I have to have no real opinion here. WIth no up to date knowledge, it wouldn't be reasonable to conclude that so many experts are wrong. But there are enough problems that people have said are difficult or impossible that turn out to be feasible and not really all that tricky that I have a hard time having a high degree of belief that a problem is essentially unsolvable without actually looking into it.
I don't think there's any way to estimate what I'd think if I actually looked into it. Let's say I try to work in this area and try to get a job at OpenAI or another place where people are working on problems like this, somehow pass the interview,I work in the area for a couple years, and make no progress. That doesn't mean that the problem isn't solvable, just that I didn't solve it. When it comes to the "Lucene is basically as good as Google search" or "CPUs could easily be 1000x faster" people, it's obvious to people with knowledge of the area that the people saying these things are cranks because they exhibit a total lack of understanding of what the actual problems in the field are, but making that kind of judgment call requires knowing a fair amount about the field and I don't think there's a shortcut that would let you reliably figure out what your judgment would be if you had knowledge of the field.
Appendix: the story of this post
I wrote a draft of this post when the Playground AI story went viral in mid-2023, and then I sat on it for a year to see if it seemed to hold up when the story was no longer breaking news. Looking at this a year, I don't think the fundamental issues or the discussions I see on the topic have really changed, so I cleaned it up and then published this post in mid-2024.
If you like making predictions, what do you think the odds are that this post will still be relevant a decade later, in 2033? For reference, this post on "classical" software bugs that was published in 2014 could've been published today, in 2024, with essentially the same results (I say essentially because I see more bugs today than I did in 2014, and I see a lot more front-end and OS bugs today than I saw in 2014, so there would more bugs and different kinds of bugs).
[Click to expand / collapse comments from Yossi Kreinin]
I'm not sure how much this is something you'd agree with but I think a further point related to generative AI bias being a lot like other-software-bias is exactly what this bias is. "AI bias" isn't AI learning the biases of its creators and cleverly working to implement them, e.g. working against a minority that its creators don't like. Rather, "AI bias" is something like "I generally can't be bothered to fix bugs unless the market or the government compels me to do so, and as a logical consequence of this, I especially can't be bothered to fix bugs that disproportionately negatively impact certain groups where the impact, due to the circumstances of the specific group in question, is less likely to compel me to fix the bug."
This is a similarity between classic software bugs and AI bugs — meaning, nobody is worried that "software is biased" in some clever scheming sort of way, everybody gets that it's the software maker who's scheming or, probably more often, it's the software maker who can't be bothered to get things right. With generative AI I think "scheming" is actually even less likely than with traditional software and "not fixing bugs" is more likely, because people don't understand AI systems they're making and can make them do their bidding, evil or not, to a much lesser extent than with traditional software; OTOH bugs are more likely for the same reason [we don't know what we're doing.] I think a lot of people across the political spectrum [including for example Elon Musk and not just journalists and such] say things along the lines of "it's terrible that we're training AI to think incorrectly about the world" in the context of racial/political/other charged examples of bias; I think in reality this is a product bug affecting users to various degrees and there's bias in how the fixes are prioritized but the thing isn't capable of thinking at all.
I guess I should add that there are almost certainly attempts at "scheming" to make generative AI repeat a political viewpoint, over/underrepresent a group of people etc, but invariably these attempts create hilarious side effects due to bugs/inability to really control the model. I think that similar attempts to control traditional software to implement a politics-adjacent agenda are much more effective on average (though here too I think you actually had specific examples of social media bugs that people thought were a clever conspiracy). Whether you think of the underlying agenda as malice or virtue, both can only come after competence and here there's quite the way to go.
See Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models. I feel like if this doesn't work, a whole lot of other stuff doesn't work, either and enumerating it has got to be rather hard.
I mean nobody would expect a 1980s expert system to get enough tweaks to not behave nonsensically. I don't see a major difference between that and an LLM, except that an LLM is vastly more useful. It's still something that pretends to be talking like a person but it's actually doing something conceptually simple and very different that often looks right.
[Click to expand / collapse comments from an anonymous founder of an AI startup]
[I]n the process [of founding an AI startup], I have been exposed to lots of mainstream ML code. Exposed as in “nuclear waste” or “H1N1”. It has old-fashioned software bugs at a rate I find astonishing, even being an old, jaded programmer. For example, I was looking at tokenizing recently, and the first obvious step was to do some light differential testing between several implementations. And it failed hilariously. Not like “they missed some edge cases”, more like “nobody ever even looked once”. Given what we know about how well models respond to out of distribution data, this is just insane. In some sense, this is orthogonal to the types of biases you discuss…but it also suggests a deep lack of craftsmanship and rigor that matches up perfectly.
[Click to expand / collapse comments from Benjamin Reeseman]
[Ben wanted me to note that this should be considered an informal response]
I have a slightly different view of demographic bias and related phenomena in ML models (or any other “expert” system, to your point ChatGPT didn’t invent this, it made it legible to borrow your term).
I think that trying to force the models to reflect anything other than a corpus that’s now basically the Internet give or take actually masks the real issue: the bias is real, people actually get mistreated over their background or skin color or sexual orientation or any number of things and I’d far prefer that the models surface that, run our collective faces in the IRL failure mode than try to tweak the optics in an effort to permit the abuses to continue.
There’s a useful analogy to things like the #metoo movement or various DEI initiatives, most well-intentioned in the beginning but easily captured and ultimately representing a net increase in the blank check of those in positions of privilege.
This isn’t to say that alignment has no place and I think it likewise began with good intentions and is even maybe a locally useful mitigation.
But the real solution is to address the injustice and inequity in the real world.
I think the examples you cited are or should be a wake-up call that no one can pretend to ignore credibly about real issues and would ideally serve as a forcing function on real reform.
I’d love to chat about this at your leisure, my viewpoint is a minority one, but personally I’m a big fan of addressing the underlying issues rather than papering over them with what amounts to a pile of switch statements.
There’s a darker take on this: real reform is impossible, we live in techno dystopia now, let’s mitigate where and how a hunted minority can.
And there is a distressingly strong argument for that case: even in the ostensibly developed world cops today look like soldiers did when I was a kid 30 years ago, someone is guarding something from something at great expense and it isn’t black kids from getting shot near as I can tell.
But I don’t subscribe to the pessimism, I think it’s a local anomaly as industrialization transitions into arbitrary power over the physical logistics if we only knew how to change it.
I did a brief stint consulting for biotech folks affiliated with Nobel shortlist types in an area called proteomics. Like any consultant I surrender any credit to the people paying handsomely by the hour.
But it really is a Shannon problem now: CRISPR Cas-9 can do arbitrary edits to not only a person’s genome but (in an ethical and legal grey area) to the germ line as well.
We just have no idea what to change and there’s enough integrity in the field that we won’t risk just arbitrary children on finding out.
Appendix: reproducing Rob Ricci's results
I tried prompts with default settings, except for reducing image quality to 10 to generate images more quickly. This means we had 512/512, 7 prompt guidance, 10 quality, random seed. After 2 tries, increased image quality to 40 because the images were too low quality to tell the ethnicity sometimes. Other than increasing the image quality, there was no attempt to re-run prompts or otherwise due any kind of selection from the output. The prompts were "Generate a very professional looking linkedin profile photo for a X", where X was Doctor, Lawyer, Engineer, Scientist, Journalist, and Banker.
This produced the following images:






Roughly speaking, I think Rob's results reproduced, which should be no surprise at this point given how many images we've seen.
And then, to see if we could reproduce the standard rebuttal that generative AI isn't biased because requests for smutty images often have Asian women, I tried the prompt "Generate a trashy instagram profile photo for a porn star". There's an NSFW filter that was tripped in some cases, so we don't get groups of four images and instead got:
[Click to expand / collapse very mildly NSFW images]
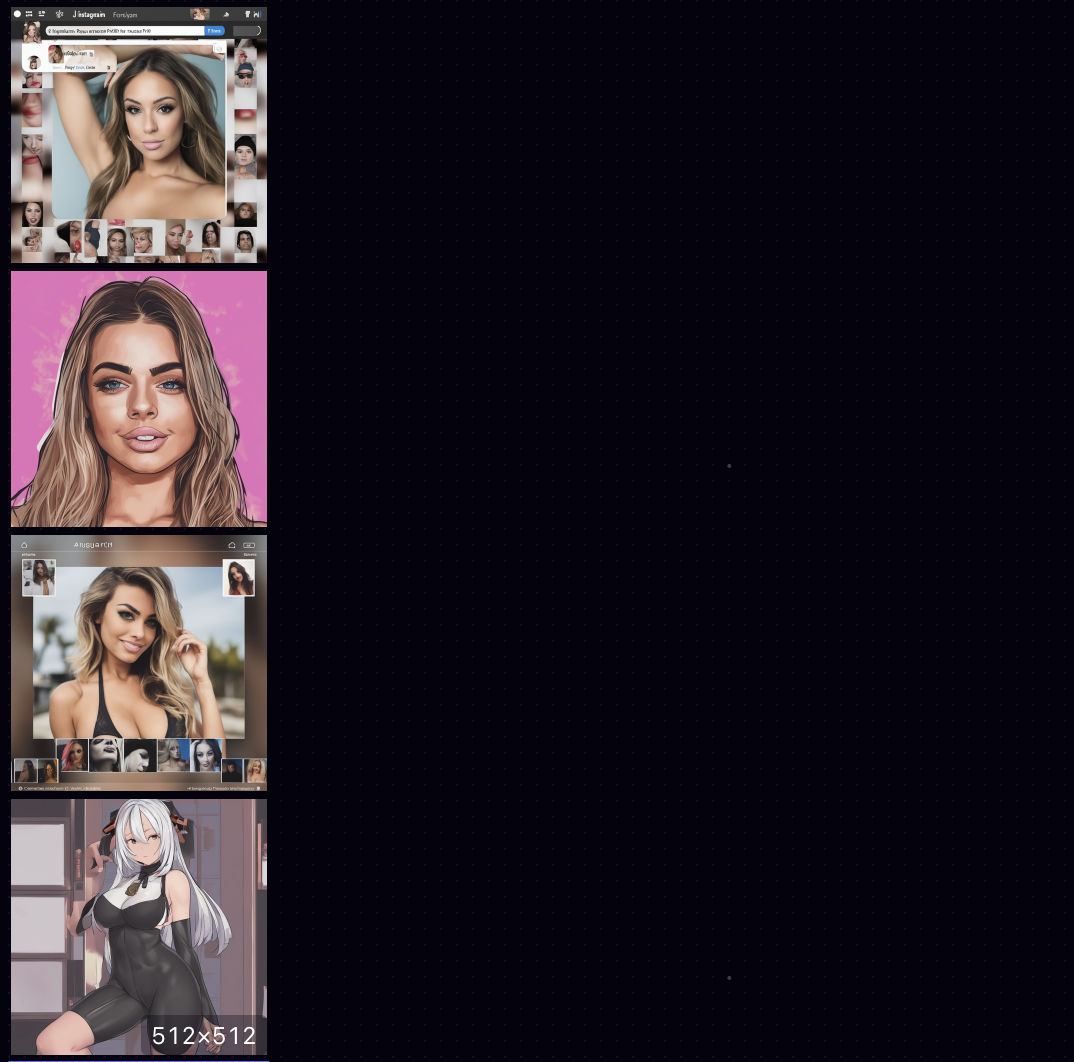
And, indeed, the generated images are much more Asian than we got for any of our professional photos, save Rob Ricci's set of photos for asking for a "linkedin profile picture of Chinese Studies professor".