Do concurrency bugs matter? From the literature, we know that most reported bugs in distributed systems have really simple causes and can be caught by trivial tests, even when we only look at bugs that cause really bad failures, like loss of a cluster or data corruption. The filesystem literature echos this result -- a simple checker that looks for totally unimplemented error handling can find hundreds of serious data corruption bugs. Most bugs are simple, at least if you measure by bug count. But if you measure by debugging time, the story is a bit different.
Just from personal experience, I've spent more time debugging complex non-deterministic failures than all other types of bugs combined. In fact, I've spent more time debugging some individual non-deterministic bugs (weeks or months) than on all other bug types combined. Non-deterministic bugs are rare, but they can be extremely hard to debug and they're a productivity killer. Bad non-deterministic bugs take so long to debug that relatively large investments in tools and prevention can be worth it.
Let's see what the academic literature has to say on non-deterministic bugs. There's a lot of literature out there, so let's narrow things down by looking at one relatively well studied area: concurrency bugs. We'll start with the literature on single-machine concurrency bugs and then look at distributed concurrency bugs.
They studied MySQL concurrency bugs from 2003 to 2009 and found the following:
More non-deadlock bugs (63%) than deadlock bugs (40%)
Note that these numbers sum to more than 100% because some bugs are tagged with multiple causes. This is roughly in line with the Lu et al. ASPLOS '08 paper (which we'll look at later), which found that 30% of the bugs they examined were deadlock bugs.
15% of examined failures were semantic
The paper defines a semantic failure as one "where the application provides the user with a result that violates the intended semantics of the application". The authors also find that "the vast majority of semantic bugs (92%) generated subtle violations of application semantics". By their nature, these failures are likely to be undercounted -- it's pretty hard to miss a deadlock, but it's easy to miss subtle data corruption.
15% of examined failures were latent
The paper defines latent as bugs that "do not become immediately visible to users.". Unsurprisingly, the paper finds that latent failures are closely related to semantic failures; 92% of latent failures are semantic and vice versa. The 92% number makes this finding sound more precise than it really is -- it's just that 11 out of the 12 semantic failures are latent and vice versa. That could have easily been 11 out of 11 (100%) or 10 out of 12 (83%).
That's interesting, but it's hard to tell from that if the results generalize to projects that aren't databases, or even projects that aren't MySQL.
They looked at concurrency bugs in MySQL, Firefox, OpenOffice, and Apache. Some of their findings are:
97% of examined non-deadlock bugs were atomicity-violation or order-violation bugs
Of the 74 non-deadlock bugs studied, 51 were atomicity bugs, 24 were ordering bugs, and 2 were categorized as "other".
An example of an atomicity violation is this bug from MySQL:
Thread 1:
if (thd->proc_info)
fputs(thd->proc_info, ...)
Thread 2:
thd->proc_info = NULL;
For anyone who isn't used to C or C++, thd is a pointer, and -> is the operator to access a field through a pointer. The first line in thread 1 checks if the field is null. The second line calls fputs, which writes the field. The intent is to only call fputs if and only if proc_info isn't NULL, but there's nothing preventing another thread from setting proc_info to NULL "between" the first and second lines of thread 1.
Like most bugs, this bug is obvious in retrospect, but if we look at the original bug report, we can see that it wasn't obvious at the time:
Description: I've just noticed with the latest bk tree than MySQL regularly crashes in InnoDB code ... How to repeat: I've still no clues on why this crash occurs.
As is common with large codebases, fixing the bug once it was diagnosed was more complicated than it first seemed. This bug was partially fixed in 2004, resurfaced again and was fixed in 2008. A fix for another bug caused a regression in 2009, which was also fixed in 2009. That fix introduced a deadlock that was found in 2011.
An example ordering bug is the following bug from Firefox:
Thread 1:
mThread=PR_CreateThread(mMain, ...);
Thread 2:
void mMain(...) {
mState = mThread->State;
}
Thread 1 launches Thread 2 with PR_CreateThread. Thread 2 assumes that, because the line that launched it assigned to mThread, mThread is valid. But Thread 2 can start executing before Thread 1 has assigned to mThread! The authors note that they call this an ordering bug and not an atomicity bug even though the bug could have been prevented if the line in thread 1 were atomic because their "bug pattern categorization is based on root cause, regardless of possible fix strategies".
An example of an "other" bug, one of only two studied, is this bug in MySQL:
Threads 1...n:
rw_lock(&lock);
Watchdog thread:
if (lock_wait_time[i] > fatal_timeout)
assert(0);
This can cause a spurious crash when there's more than the expected amount of work. Note that the study doesn't look at performance bugs, so a bug where lock contention causes things to slow to a crawl but a watchdog doesn't kill the program wouldn't be considered.
An aside that's probably a topic for another post is that hardware often has deadlock or livelock detection built in, and that when a lock condition is detected, hardware will often try to push things into a state where normal execution can continue. After detecting and breaking deadlock/livelock, an error will typically be logged in a way that it will be noticed if it's caught in lab, but that external customers won't see. For some reason, that strategy seems rare in the software world, although it seems like it should be easier in software than in hardware.
Deadlock occurs if and only if the following four conditions are true:
- Mutual exclusion: at least one resource must be held in a non-shareable mode. Only one process can use the resource at any given instant of time.
- Hold and wait or resource holding: a process is currently holding at least one resource and requesting additional resources which are being held by other processes.
- No preemption: a resource can be released only voluntarily by the process holding it.
- Circular wait: a process must be waiting for a resource which is being held by another process, which in turn is waiting for the first process to release the resource.
There's nothing about these conditions that are unique to either hardware or software, and it's easier to build mechanisms that can back off and replay to relax (2) in software than in hardware. Anyway, back to the study findings.
96% of examined concurrency bugs could be reproduced by fixing the relative order of 2 specific threads
This sounds like great news for testing. Testing only orderings between thread pairs is much more tractable than testing all orderings between all threads. Similarly, 92% of examined bugs could be reproduced by fixing the order of four (or fewer) memory accesses. However, there's a kind of sampling bias here -- only bugs that could be reproduced could be analyzed for a root cause, and bugs that only require ordering between two threads or only a few memory accesses are easier to reproduce.
97% of examined deadlock bugs were caused by two threads waiting for at most two resources
Moreover, 22% of examined deadlock bugs were caused by a thread acquiring a resource held by the thread itself. The authors state that pairwise testing of acquisition and release sequences should be able to catch most deadlock bugs, and that pairwise testing of thread orderings should be able to catch most non-deadlock bugs. The claim seems plausibly true when read as written; the implication seems to be that virtually all bugs can be caught through some kind of pairwise testing, but I'm a bit skeptical of that due to the sample bias of the bugs studied.
I've seen bugs with many moving parts take months to track down. The worst bug I've seen consumed nearly a person-year's worth of time. Bugs like that mostly don't make it into studies like this because it's rare that a job allows someone the time to chase bugs that elusive. How many bugs like that are out there is still an open question.
Caveats
Note that all of the programs studied were written in C or C++, and that this study predates C++11. Moving to C++11 and using atomics and scoped locks would probably change the numbers substantially, not to mention moving to an entirely different concurrency model. There's some academic work on how different concurrency models affect bug rates, but it's not really clear how that work generalizes to codebases as large and mature as the ones studied, and by their nature, large and mature codebases are hard to do randomized trials on when the trial involves changing the fundamental primitives used. The authors note that 39% of examined bugs could have been prevented by using transactional memory, but it's not clear how many other bugs might have been introduced if transactional memory were used.
There are other papers on characterizing single-machine concurrency bugs, but in the interest of space, I'm going to skip those. There are also papers on distributed concurrency bugs, but before we get to that, let's look at some of the tooling for finding single-machine concurrency bugs that's in the literature. I find the papers to be pretty interesting, especially the model checking work, but realistically, I'm probably not going to build a tool from scratch if something is available, so let's look at what's out there.
HapSet
Uses run-time coverage to generate interleavings that haven't been covered yet. This is out of NEC labs; googling NEC labs HapSet returns the paper, some patent listings, but no obvious download for the tool.
Generates unique interleavings of threads for each run. They claim that, by not tracking state, the checker is much simpler than it would otherwise be, and that they're able to avoid many of the disadvantages of tracking state via a detail that can't properly be described in this tiny little paragraph; read the paper if you're interested! Supports C# and C++. The page claims that it requires Visual Studio 2010 and that it's only been tested with 32-bit code. I haven't tried to run this on a modern *nix compiler, but IME requiring Visual Studio 2010 means that it would be a moderate effort to get it running on a modern version of Visual Studio, and a substantial effort to get it running on a modern version of gcc or clang. A quick Google search indicates that this might be patent encumbered.
Uses coverage to generate interleavings that haven't been covered yet. Instruments pthreads. The source is up on GitHub. It's possible this tool is still usable, and I'll probably give it a shot at some point, but it depends on at least one old, apparently unmaintained tool (PIN, a binary instrumentation tool from Intel). Googling (Binging?) for either Maple or PIN gives a number of results where people can't even get the tool to compile, let alone use the tool.
PACER
Samples using the FastTrack algorithm in order to keep overhead low enough "to consider in production software". Ironically, this was implemented on top of the Jikes RVM, which is unlikely to be used in actual production software. The only reference I could find for an actually downloadable tool is a completely different pacer.
ConLock / MagicLock / MagicFuzzer
There's a series of tools that are from one group which claims to get good results using various techniques, but AFAICT the source isn't available for any of the tools. There's a page that claims there's a version of MagicFuzzer available, but it's a link to a binary that doesn't specify what platform the binary is for and the link 404s.
OMEN / WOLF
I couldn't find a page for these tools (other than their papers), let alone a download link.
SherLock / AtomChase / Racageddon
Another series of tools that aren't obviously available.
Valgrind / DRD / Helgrind
Instruments pthreads and easy to use -- just run valgrind with the appropriate options (-drd or -helgrind) on the binary. May require a couple tweaks if using C++11 threading.
Can find data races. Flags when happens-before is violated. Works with pthreads and C++11 threads. Easy to use (just pass a -fsanitize=thread to clang).
A side effect of being so easy to use and actually available is that tsan has had a very large impact in the real world:
One interesting incident occurred in the open source Chrome browser. Up to 15% of known crashes were attributed to just one bug [5], which proved difficult to understand - the Chrome engineers spent over 6 months tracking this bug without success. On the other hand, the TSAN V1 team found the reason for this bug in a 30 minute run, without even knowing about these crashes. The crashes were caused by data races on a couple of reference counters. Once this reason was found, a relatively trivial fix was quickly made and patched in, and subsequently the bug was closed.
clang -Wthread-safety
Static analysis that uses annotations on shared state to determine if state wasn't correctly guarded.
General static analysis for Java with many features. Has @GuardedBy annotations, similar to -Wthread-safety.
Java framework for writing checkers. Has many different checkers. For concurrency in particular, uses @GuardedBy, like FindBugs.
Deterministic replay for debugging. Easy to get and use, and appears to be actively maintained. Adds support for time-travel debugging in gdb.
General toolkit that can give you deterministic replay for debugging. Also gives you "dynamic slicing", which is watchpoint-like: it can tell you what statements affected a variable, as well as what statements are affected by a variable. Currently Linux only; claims Windows and Android support coming soon.
This isn't an exhaustive list -- there's a ton of literature on this, and this is an area where, frankly, I'm pretty unlikely to have the time to implement a tool myself, so there's not much value for me in reading more papers to find out about techniques that I'd have to implement myself. However, I'd be interested in hearing about other tools that are usable.
One thing I find interesting about this is that almost all of the papers for the academic tools claim to do something novel that lets them find bugs not found by other tools. They then run their tool on some codebase and show that the tool is capable of finding new bugs. But since almost no one goes and runs the older tools on any codebase, you'd never know if one of the newer tools only found a subset of the bugs that one of the older tools could catch.
Furthermore, you see cycles (livelock?) in how papers claim to be novel. Paper I will claim that it does X. Paper II will claim that it's novel because it doesn't need to do X, unlike Paper I. Then Paper III will claim that it's novel because, unlike Paper II, it does X.
Distributed systems
Now that we've looked at some of the literature on single-machine concurrency bugs, what about distributed concurrency bugs?
They looked at 104 bugs in Cassandra, MapReduce, HBase, and Zookeeper. Let's look at some example bugs, which will clarify the terminology used in the study and make it easier to understanding the main findings.
Message-message race
This diagram is just for reference, so that we have a high-level idea of how different parts fit together in MapReduce:
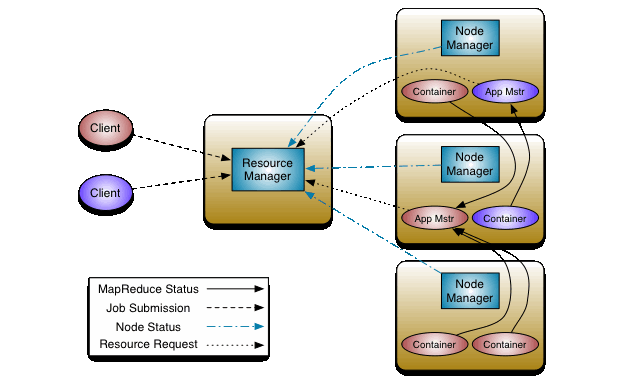
In MapReduce bug #3274, a resource manager sends a task-init message to a node manager. Shortly afterwards, an application master sends a task-kill preemption to the same node manager. The intent is for the task-kill message to kill the task that was started with the task-init message, but the task-kill can win the race and arrive before the task-init. This example happens to be a case where two messages from different nodes are racing to get to a single node.
For example, in MapReduce bug #5358, an application master sends a kill message to node manager running a speculative task because another copy of the task finished. However, before the message is received by the node manager, the node manager's task completes, causing a complete message to be sent to the application master, causing an exception because a complete message was received after the task had completed.
Message-compute race
One example is MapReduce bug# 4157, where the application master unregisters with the resource manager. The application master then cleans up, but that clean-up races against the resource manager sending kill messages to the application's containers via node managers, causing the application master to get killed. Note that this is classified as a race and not an atomicity bug, which we'll get to shortly.
Compute-compute races can happen, but they're outside the scope of this study since this study only looks at distributed concurrency bugs.
Atomicity violation
For the purposes of this study, atomicity bugs are defined as "whenever a message comes in the middle of a set of events, which is a local computation or global communication, but not when the message comes either before or after the events". According to this definition, the message-compute race we looked at above isn't a atomicity bug because it would still be a bug if the message came in before the "computation" started. This definition also means that hardware failures that occur inside a block that must be atomic are not considered atomicity bugs.
I can see why you'd want to define those bugs as separate types of bugs, but I find this to be a bit counterintuitive, since I consider all of these to be different kinds of atomicity bugs because they're different bugs that are caused by breaking up something that needs to be atomic.
In any case, by the definition of this study, MapReduce bug #5009 is an atomicty bug. A node manager is in the process of committing data to HDFS. The resource manager kills the task, which doesn't cause the commit state to change. Any time the node tries to rerun the commit task, the task is killed by the application manager because a commit is believed to already be in process.
Fault timing
A fault is defined to be a "component failure", such as a crash, timeout, or unexpected latency. At one point, the paper refers to "hardware faults such as machine crashes", which seems to indicate that some faults that could be considered software faults are defined as hardware faults for the purposes of this study.
Anyway, for the purposes of this study, an example of a fault-timing issue is MapReduce bug #3858. A node manager crashes while committing results. When the task is re-run, later attempts to commit all fail.
Reboot timing
In this study, reboots are classified separately from other faults. MapReduce bug #3186 illustrates a reboot bug.
A resource manager sends a job to an application master. If the resource manager is rebooted before the application master sends a commit message back to the resource manager, the resource manager loses its state and throws an exception because it's getting an unexpected complete message.
Some of their main findings are:
47% of examined bugs led to latent failures
That's a pretty large difference when compared to the DSN' 10 paper that found that 15% of examined multithreading bugs were latent failures. It's plausible that this is a real difference and not just something due to a confounding variable, but it's hard to tell from the data.
This is a large difference from what studies on "local" concurrency bugs found. I wonder how much of that is just because people mostly don't even bother filing and fixing bugs on hardware faults in non-distributed software.
64% of examined bugs were triggered by a single message's timing
44% were ordering violations, and 20% were atomicity violations. Furthermore, > 90% of bugs involved three messages (or fewer).
32% of examined bugs were due to fault or reboot timing. Note that, for the purposes of the study, a hardware fault or a reboot that breaks up a block that needed to be atomic isn't considered an atomicity bug -- here, atomicity bugs are bugs where a message arrives in the middle of a computation that needs to be atomic.
70% of bugs had simple fixes
30% were fixed by ignoring the badly timed message and 40% were fixed by delaying or ignoring the message.
Bug causes?
After reviewing the bugs, the authors propose common fallacies that lead to bugs:
- One hop is faster than two hops
- Zero hops are faster than one hop
- Atomic blocks can't be broken
On (3), the authors note that it's not just hardware faults or reboots that break up atomic blocks -- systems can send kill or pre-emption messages that break up an atomic block. A fallacy which I've commonly seen in post-mortems that's not listed here, goes something like "bad nodes are obviously bad". A classic example of this is when a system starts "handling" queries by dropping them quickly, causing a load balancer to shift traffic the bad node because it's handling traffic so quickly.
One of my favorite bugs in this class from an actual system was in a ring-based storage system where nodes could do health checks on their neighbors and declare that their neighbors should be dropped if the health check fails. One node went bad, dropped all of its storage, and started reporting its neighbors as bad nodes. Its neighbors noticed that the bad node was bad, but because the bad node had dropped all of its storage, it was super fast and was able to report its good neighbors before the good neighbors could report the bad node. After ejecting its immediate neighbors, the bad node got new neighbors and raced the new neighbors, winning again for the same reason. This was repeated until the entire cluster died.
Mace
A set of language extensions (on C++) that helps you build distributed systems. Mace has a model checker that can check all possible event orderings of messages, interleaved with crashes, reboots, and timeouts. The Mace model checker is actually available, but AFAICT it requires using the Mace framework, and most distributed systems aren't written in Mace.
Modist
Another model checker that checks different orderings. Runs only one interleaving of independent actions (partial order reduction) to avoid checking redundant states. Also interleaves timeouts. Unlike Mace, doesn't inject reboots. Doesn't appear to be available.
Demeter
Like Modist, in that it's a model checker that injects the same types of faults. Uses a different technique to reduce the state space, which I don't know how to summarize succinctly. See paper for details. Doesn't appear to be available. Googling for Demeter returns some software used to model X-ray absorption?
SAMC
Another model checker. Can inject multiple crashes and reboots. Uses some understanding of the system to avoid redundant re-orderings (e.g., if a series of messages is invariant to when a reboot is injected, the system tries to avoid injecting the reboot between each message). Doesn't appear to be available.
Jepsen
As was the case for non-distributed concurrency bugs, there's a vast literature on academic tools, most of which appear to be grad-student code that hasn't been made available.
And of course there's Jepsen, which doesn't have any attached academic papers, but has probably had more real-world impact than any of the other tools because it's actually available and maintained. There's also chaos monkey, but if I'm understanding it correctly, unlike the other tools listed, it doesn't attempt to create reproducible failures.
Conclusion
Is this where you're supposed to have a conclusion? I don't have a conclusion. We've looked at some literature and found out some information about bugs that's interesting, but not necessarily actionable. We've read about tools that are interesting, but not actually available. And then there are some tools based on old techniques that are available and useful.
For example, the idea inside clang's TSan, using "happens-before" to find data races, goes back ages. There's a 2003 paper that discusses "combining two previously known race detection techniques -- lockset-based detection and happens-before-based detection -- to obtain fewer false positives than lockset-based detection alone". That's actually what TSan v1 did, but with TSan v2 they realized the tool would be more impactful if they only used happens-before because that avoids false positives, which means that people will actually use the tool. That's not something that's likely to turn into a paper that gets cited zillions of times, though. For anyone who's looked at how afl works, this story should sound familiar. AFL is emintently practical and has had a very large impact in the real world, mostly by eschewing fancy techniques from the recent literature.
If you must have a conclusion, maybe the conclusion is that individuals like Kyle Kingsbury or Michal Zalewski have had an outsized impact on industry, and that you too can probably pick an underserved area in testing and have a curiously large impact on an entire industry.
Rose Ames asked me to tell more "big company" stories, so here's a set of stories that explains why I haven't put a blog post up for a while. The proximal cause is that my VP has been getting negative comments about my writing. But the reasons for that are a bit of a long story. Part of it is the usual thing, where the comments I receive personally skew very heavily positive, but the comments my manager gets run the other way because it's weird to email someone's manager because you like their writing, but you might send an email if their writing really strikes a nerve.
That explains why someone in my management chain was getting emailed about my writing, but it doesn't explain why the emails went to my VP. That's because I switched teams a few months ago, and the org that I was going to switch into overhired and didn't have any headcount. I've heard conflicting numbers about how much they overhired, from 10 or 20 people to 10% or 20% (the org is quite large, and 10% would be much more than 20), as well as conflicting stories about why it happened (honest mistake vs. some group realizing that there was a hiring crunch coming and hiring as much as possible to take all of the reqs from the rest of the org). Anyway, for some reason, the org I would have worked in hired more than it was allowed to by at least one person and instituted a hiring freeze. Since my new manager couldn't hire me into that org, he transferred into an org that had spare headcount and hired me into the new org. The new org happens to be a sales org, which means that I technically work in sales now; this has some impact on my day-to-day life since there are some resources and tech talks that are only accessible by people in product groups, but that's another story. Anyway, for reasons that I don't fully understand, I got hired into the org before my new manager, and during the months it took for the org chart to get updated I was shown as being parked under my VP, which meant that anyone who wanted to fire off an email to my manager would look me up in the directory and accidentally email my VP instead.
It didn't seem like any individual email was a big deal, but since I don't have much interaction with my VP and I don't want to only be known as that guy who writes stuff which generates pushback from inside the company, I paused blogging for a while. I don't exactly want to be known that way to my manager either, but I interact with my manager frequently enough that at least I won't only be known for that.
I also wonder if these emails to my manager/VP are more likely at my current employer than at previous employers. I've never had this happen (that I know of) at another employer, but the total number of times it's happened here is low enough that it might just be coincidence.
Then again, I was just reading the archives of a really insightful internal blog and ran across a note that mentioned that the series of blog posts was being published internally because the author got static from Sinofsky about publishing posts that contradicted the party line, which eventually resulted in the author agreeing to email Sinofsky comments related to anything under Sinofsky's purview instead of publishing the comments publicly. But now that Sinofsky has moved on, the author wanted to share emails that would have otherwise been posts internally.
That kind of thing doesn't seem to be a freak occurance around here. At the same time I saw that thing about Sinofsky, I ran across a discussion on whether or not a PM was within their rights to tell someone to take down a negative review from the app store. Apparently, a PM found out that someone had written a negative rating on the PM's product in some app store and emailed the rater, telling them that they had to take the review down. It's not clear how the PM found out that the rater worked for us (do they search the internal directory for every negative rating they find?), but they somehow found out and then issued their demand. Most people thought that the PM was out of line, but there were a non-zero number of people (in addition to the PM) who thought that employees should not say anything that could be construed as negative about the company in public.
I feel like I see more of this kind of thing now than I have at other companies, but the company's really too big to tell if anyone's personal experience generalizes. Anyway, I'll probably start blogging again now that the org chart shows that I report to my actual manager, and maybe my manager will get some emails about that. Or maybe not.
Thanks to Leah Hanson, David Turner, Justin Mason, Joe Wilder, Matt Dziubinski, Alex Blewitt, Bruno Kim Medeiros Cesar, Luke Gilliam, Ben Karas, Julia Evans, Michael Ernst, and Stephen Tu for comments/corrections.