Here's the graph of a toy benchmark of page-aligned vs. mis-aligned accesses; it shows a ratio of performance between the two at different working set sizes. If this benchmark seems contrived, it actually comes from a real world example of the disastrous performance implications of using nice power of 2 alignment, or page alignment in an actual system.
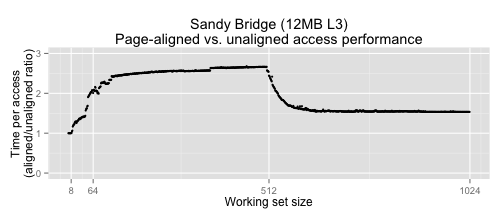
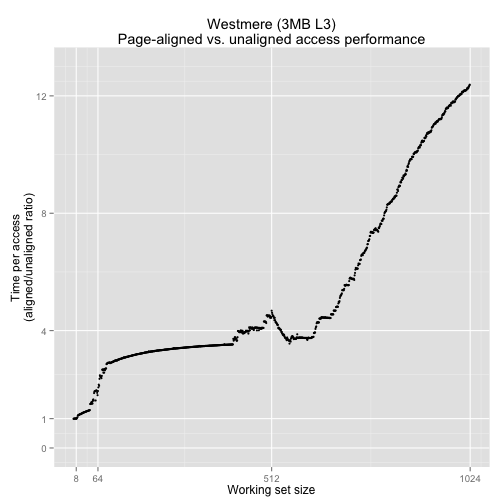
Except for very small working sets (1-8), the unaligned version is noticeably faster than the page-aligned version, and there's a large region up to a working set size of 512 where the ratio in performance is somewhat stable, but more so on our Sandy Bridge chip than our Westmere chip.
To understand what's going on here, we have to look at how caches organize data. By way of analogy, consider a 1,000 car parking garage that has 10,000 permits. With a direct mapped scheme (which you could call 1-way associative), each of the ten permits that has the same 3 least significant digits would be assigned the same spot, i.e., permits 0618, 1618, 2618, and so on, are only allowed to park in spot 618. If you show up at your spot and someone else is in it, you kick them out and they have to drive back home. The next time they get called in to work, they have to drive all the way back to the parking garage.
Instead, if each car's permit allows it to park in a set that has ten possible spaces, we'll call that a 10-way set associative scheme, which gives us 100 sets of ten spots. Each set is now defined by the last 2 significant digits instead of the last 3. For example, with permit 2618, you can park in any spot from the set {018, 118, 218, …, 918}. If all of them are full, you kick out one unlucky occupant and take their spot, as before.
Let's move out of analogy land and back to our benchmark. The main differences are that there isn't just one garage-cache, but a hierarchy of them, from the L1, which is the smallest (and hence, fastest) to the L2 and L3. Each seat in a car corresponds to an address. On x86, each addresses points to a particular byte. In the Sandy Bridge chip we're running on, we've got a 32kB L1 cache with 64-byte line size and, 64 sets, with 8-way set associativity. In our analogy, a line size of 64 would correspond to a car with 64 seats. We always transfer things in 64-byte chunks and the bottom log₂(64) = 6 bits of an address refer to a particular byte offset in a cache line. The next log₂(64) = 6 bits determine which set an address falls into. Each of those sets can contain 8 different things, so we have 64 sets * 8 lines/set * 64 bytes/line = 32kB. If we use the cache optimally, we can store 32,768 items. But, since we're accessing things that are page (4k) aligned, we effectively lose the bottom log₂(4k) = 12 bits, which means that every access falls into the same set, and we can only loop through 8 things before our working set is too large to fit in the L1! But if we'd misaligned our data to different cache lines, we'd be able to use 8 * 64 = 512 locations effectively.
Similarly, our chip has a 512 set L2 cache, of which 8 sets are useful for our page aligned accesses, and a 12288 set L3 cache, of which 192 sets are useful for page aligned accesses, giving us 8 sets * 8 lines / set = 64 and 192 sets * 8 lines / set = 1536 useful cache lines, respectively. For data that's misaligned by a cache line, we have an extra 6 bits of useful address, which means that our L2 cache now has 32,768 useful locations.
In the Sandy Bridge graph above, there's a region of stable relative performance between 64 and 512, as the page-aligned version version is running out of the L3 cache and the unaligned version is running out of the L1. When we pass a working set of 512, the relative ratio gets better for the aligned version because it's now an L2 access vs. an L3 access. Our graph for Westmere looks a bit different because its L3 is only 3072 sets, which means that the aligned version can only stay in the L3 up to a working set size of 384. After that, we can see the terrible performance we get from spilling into main memory, which explains why the two graphs differ in shape above 384.
For a visualization of this, you can think of a 32 bit pointer looking like this to our L1 and L2 caches:
TTTT TTTT TTTT TTTT TTTT SSSS SSXX XXXX
TTTT TTTT TTTT TTTT TSSS SSSS SSXX XXXX
The bottom 6 bits are ignored, the next bits determine which set we fall into, and the top bits are a tag that let us know what's actually in that set. Note that page aligning things, i.e., setting the address to
???? ???? ???? ???? ???? 0000 0000 0000
was just done for convenience in our benchmark. Not only will aligning to any large power of 2 cause a problem, generating addresses with a power of 2 offset from each other will cause the same problem.
Nowadays, the importance of caches is well understood enough that, when I'm asked to look at a cache related performance bug, it's usually due to the kind of thing we just talked about: conflict misses that prevent us from using our full cache effectively. This isn't the only way for that to happen -- bank conflicts and and false dependencies are also common problems, but I'll leave those for another blog post.
Resources
For more on caches on memory, see What Every Programmer Should Know About Memory. For something with more breadth, see this blog post for something "short", or Modern Processor Design for something book length. For even more breadth (those two links above focus on CPUs and memory), see Computer Architecture: A Quantitative Approach, which talks about the whole system up to the datacenter level.